I had the opportunity to connect with several professionals in higher education, education technology and AI in education, and I learned a lot about the challenges and opportunities in the field.
As a company providing custom AI solutions, it’s very important that we understand the needs of institutions, educators and students, their concerns regarding artificial intelligence, and how we can help them leverage AI to solve real problems while protecting privacy and ensuring fairness.
The event offered a packed program, with several talks, workshops, networking opportunities and a large expo. The networking opportunities were especially helpful, with several facilitated meetups happening that gave me an opportunity to talk to other agencies doing work in the space, ed tech providers, educators, administrators and researches in the space.
My perception overall was of a very AI-positive audience, with a lot of interest in how AI can help improve education, curiosity over capabilities and limitations of AI, and several great discussions around potential risks, strategies to mitigate them, and how AI can be made safe for education institutions.

SXSW Expo and Interesting Solutions in the Space
Artificial intelligence has already arrived in the classrooms, be it in K-12 or higher education. AI is being used to enhance learning through interactive content, personalize learning paths through AI-powered tutors that respond to student’s individual needs, generate class plans and activities to help educators save time, among other applications.
The Expo was full of companies showcasing their AI-powered solutions, as well as AI-focused courses and learning resources.

A great insight from talking to companies in the space is that a lot of AI adoption in education process seems to be driven by students.
Students find the solutions, use them, and then bring them to the attention of their teachers and institutions, advocating for the value they provide.
There weren’t, however, solutions focused on helping automate administrative tasks for universities, or focused on helping institutions make more data-driven decisions and improve the services they provide with artificial intelligence. This is a gap we are looking to fill with our custom AI solutions, tailored to the individual needs of different universities and departments.
An interesting aspect of the Expo were the many products focused on K-12 education and, especially, younger students.
It is interesting to see different products designed to get children engaged with technology. This helps us build an understanding of how the younger generations are taught to interact with technology in general and artificial intelligence specifically, and how that relationship might shape how schools and universities need to approach AI.
AI in Education: Challenges and Opportunities
Another very interesting aspect of the event was the networking lounge. It provided a structured space to allow different groups of people interested in similar topics to sit down for an hour and discuss.

I had the opportunity to discuss challenges for AI in education with a company providing AI-powered tutoring solutions, a researcher studying the impact of AI in education, and a group of educators interested in better understand the actual risks involved with AI.
Some of the key challenges discussed were the need for more transparency in AI solutions, the concern for data privacy and security and a disconnect between institutions and students when it comes to the technology and how to approach it.
Discussions like this help us understand the pain points in the industry and tailor our solutions to meet the specific needs of the institutions we support, providing proper risk management and peace of mind.
Conclusion
South by Southwest EDU was an amazing event, with a lot of shared knowledge, experience, and interesting discussions.
It’s clear there are many opportunities in higher education to leverage artificial intelligence, not only for students and student experience, but for educators, researchers, and administrative departments.
Want to see how AI can help you? Contact us today!
]]>uv package manager that’s been talked about a lot.
One problem with that, though, is that lack of support for uv in Heroku’s Python buildpacks. There’s an issue open in the Heroku roadmap to support it, but it is not supported yet.
We weren’t going to let that little hiccup stop us from using uv though. Inspired by the python-poetry-buildpack, we built our own little heroku-uv-buildpack that allowed us to deploy our application to Heroku.
Created by Astral, the same folks behind the ruff linter and formatter, uv is a very powerful package manager (and more) that allows you to easily manage your Python environments and dependencies.
Our focus here is on the buildpack, but if you’re curious to read more about the tool, check out this uv Deep Dive article by SaaS Pegasus.
Heroku Buildpacks
Per Heroku’s documentation on buildpacks:
Buildpacks are a set of scripts that transform code into a deployable artifact with minimal configuration that gets executed on a dyno.
Heroku has officially supported buildpacks that provide support for several languages and frameworks, including Python. It also allows you to create custom buildpacks and to compose multiple buildpacks, which run in sequence.
We’ll take advantage of this ability to compose buildpacks. Instead of creating a brand new Python buildpack that supports uv, we’ll just create a small buildpack that prepares the resources the official Heroku Python buildpack is expecting from our uv-specific files.
Buildpack Composition
A buildpack consists of three scripts:
bin/detect: determines whether the buildpack should be applied to an application.bin/compile: performs the transformation steps on the application. This defines what our buildpack actually does.bin/release: provides metadata that is sent back to the runtime.
We’ll define bin/detect and bin/compile. We don’t really need bin/release for our purposes here.
bin/detect
This is what determines whether to apply our buildpack to an app or not. In our case, all of our transformations rely on the application having a uv.lock file. So our bin/detect script will simply check if one is present and, if not, exit with an error:
#!/usr/bin/env bash
set -euo pipefail
BUILD_DIR="$1"
if [ ! -f "$BUILD_DIR/uv.lock" ] ; then
exit 1
fi
echo "Python uv"
bin/compile
This is where the steps the buildpack will apply to the application are defined. In order to get the resources in place the Heroku Python buildpack needs, we’ll perform two transformations:
- Generate a
requirements.txtfile withuv - Generate a
runtime.txtfile
Install uv
The first thing we need to do is install the right version uv. A specific uv version can be set using a UV_VERSION config var. If a UV_VERSION is not specified, we’ll default to latest:
UV_VERSION="${UV_VERSION:-}"
if [ -z "$UV_VERSION" ] ; then
log "No uv version specified in the UV_VERSION config var. Defaulting to latest."
else
log "Using uv version from UV_VERSION config var: $UV_VERSION"
fi
With the version set, we can download and install uv. At this stage, we don’t have Python (or pip) installed. We’ll just use the curl option to install uv:
log "Install uv"
if [ -n "$UV_VERSION" ]; then
UV_URL="https://astral.sh/uv/$UV_VERSION/install.sh"
else
UV_URL="https://astral.sh/uv/install.sh"
fi
if ! curl -LsSf "$UV_URL" | sh ; then
echo "Error: Failed to install uv."
exit 1
fi
If installed successfully, we then need to add it to the PATH and it will be ready to use!
log "Add uv to the PATH"
export PATH="/app/.local/bin:$PATH"
Generate requirements.txt
Now we can generate the requirements.txt file using uv. We’ll leverage it’s support of pip commands:
log "Export $REQUIREMENTS_FILE from uv"
cd "$BUILD_DIR"
uv venv
source .venv/bin/activate
if [ "${UV_EXPORT_DEV_REQUIREMENTS:-0}" == "0" ] ; then
uv sync --no-dev
else
uv sync
fi
uv pip freeze > requirements.txt
We’re doing a few things there.
First, we navigate to the location of the app (BUILD_DIR) and then create and activate a virtual environment.
The buildpack provides an option to control whether development dependencies should be installed or not, UV_EXPORT_DEV_REQUIREMENTS. We check if it is set or not and run the appropriate version of the uv sync command.
Finally, we leverage pip freeze to create the requirements.txt file.
Generate runtime.txt
With the requirements.txt file created, we’ve completed the first transformation we set out to do. Let’s move on to the second, creating the runtime.txt file.
If you’d rather create the runtime.txt file in your repository and skip this step, you can set DISABLE_UV_CREATE_RUNTIME_FILE to 1. We’ll check to see if it is set and skip generation if it is:
if [ "${DISABLE_UV_CREATE_RUNTIME_FILE:-0}" != "0" ] ; then
log "Skip generation of $RUNTIME_FILE file from uv.lock"
exit 0
fi
If it is not set, however, a runtime.txt file should not already be present. If it is, we’ll exit with an error:
if [ -f "$RUNTIME_FILE" ] ; then
log "$RUNTIME_FILE found, delete this file from your repository!" >&2
exit 1
fi
In order to create that file, we need to define the Python runtime version. It is possible to force a Python version by setting the PYTHON_RUNTIME_VERSION config var. If it is not set, the Python runtime version will be taken from the uv.lock file:
if [ -z "${PYTHON_RUNTIME_VERSION:-}" ] ; then
log "Read Python version from uv.lock"
PYTHON_RUNTIME_VERSION=$(head --lines=2 "uv.lock" | sed -nE 's/^requires-python[[:space:]]*=[[:space:]]*"==([0-9.]+)"/\1/p')
else
log "Force Python version to $PYTHON_RUNTIME_VERSION since the $PYTHON_RUNTIME_VERSION environment variable is set!"
fi
Finally, if we find a runtime version, we create the runtime.txt:
if [[ -n "$PYTHON_RUNTIME_VERSION" ]] ; then
log "PYTHON_RUNTIME_VERSION is set to $PYTHON_RUNTIME_VERSION"
echo "python-$PYTHON_RUNTIME_VERSION" > "$RUNTIME_FILE"
else
log "$PYTHON_RUNTIME_VERSION is not valid, please specify an exact Python version (e.g. ==3.12.6) in your pyproject.toml (so it can be properly set in uv.lock)" >&2
exit 1
fi
Using the buildpack
This buildpack needs to be used together with Heroku’s official Python buildpack. You can add buildpacks to Heroku using the Heroku CLI and buildpacks:add:
heroku buildpacks:clear
heroku buildpacks:add https://github.com/ombulabs/heroku-uv-buildpack
heroku buildpacks:add heroku/python
With the buildpacks in place, you can now deploy your Python application with uv to Heroku.
At the same time we are proud of our commitment to diversity, equity, and inclusion. As part of our core values we believe that diverse teams are smarter teams:
“There is value in all types of diversity, it is the best way to stay competitive in our industry. Problem solving with minds from different backgrounds leads to more creative and better thought out solutions.”
Recent changes in Twitter (now X) and their leadership are not aligned with our core values. We believe they are taking the social network in the wrong direction and we don’t want to have our brand associated with it anymore.
That’s why starting on February 1st, we are going to publish our content primarily in these social networks:
- Mastodon
We encourage you to follow our official accounts in those platforms. Here is a link to all of them:
FastRuby.io
- Mastodon: https://ruby.social/@fastruby
- LinkedIn: https://www.linkedin.com/showcase/upgrade-rails
OmbuLabs
- Mastodon: https://mastodon.online/@ombulabs
- LinkedIn: https://www.linkedin.com/company/ombu-labs
UpgradeJS
- Mastodon: https://mastodon.online/@UpgradeJS
- LinkedIn: https://www.linkedin.com/company/upgrade-javascript
We are not planning to delete our profiles from X because we don’t want anyone to impersonate us and spread misinformation in that social network.
At the top of our X profiles, you will find a pinned post that points to this article to explain why we don’t plan to post to that platform anymore.
Thank you for understanding! I hope you will follow our social media accounts on Mastodon and LinkedIn.
]]>Prompt Engineering is a technique that focuses on perfecting your input to get the best possible output out of the language model. Of all the different techniques available to get LLMs to fit your use case best, it’s the most straightforward one to implement since it focuses primarily on improving the content of the input. In this Part I article, we’ll dive into different Prompt Engineering techniques and how to leverage them to write highly effective prompts, focusing on single prompt and chain techniques. In our following article, we’ll cover agents and multi-modal techniques.
For other available techniques to enhance LLM capabilities, check out our Techniques to Enhance the Capabilities of LLMs for your Specific Use Case article!
New to LLMs? Check out this article on the landscape by our friends over at Shift: Guest Post: Navigating the AI Chatbot Landscape.
A prompt is the input you provide to a generative model to produce an output. A successful prompt typically has four key components: instructions, context, input data, and an output indicator. These components ensure the model receives enough information in the input to provide the desired output.
Prompt engineering is refining the prompt to produce the desired output in specific scenarios without needing to update the actual model. As tasks and scenarios handled by LLMs become increasingly complex, different techniques emerge to help obtain the best results from an LLM. Some of these techniques can be applied directly while interacting with an LLM through a provided interface, such as ChatGPT (for GPT-3 and GPT-4), while others are best suited for LLM integration into new or existing systems.
Before we dive into these techniques, it’s important to keep two things in mind:
- Different LLMs will respond differently to the same prompt. Techniques that might be effective with one model won’t necessarily perform as well with a different model (or even a different version of the same model).
- Prompts are task-specific, as are some of the techniques covered here. Some are general ways to construct and use prompts and can be adapted to different scenarios, while others focus specifically on a type of task.
Let’s dive into some interesting prompt engineering techniques to help you construct powerful prompts.
Single Prompt Techniques
Single prompt techniques involve a single prompt being crafted to produce an output. The most common techniques in this category are zero-shot, few-shot, and chain of thought (CoT) prompting. These have been covered in the previous article in this series, Techniques to Enhance the Capabilities of LLMs for your Specific Use Case.
Below, we’ll cover two additional single prompt techniques.
Emotional Prompting
The idea behind this approach is to add an emotional stimulus to the prompt to elicit a better response from an LLM.
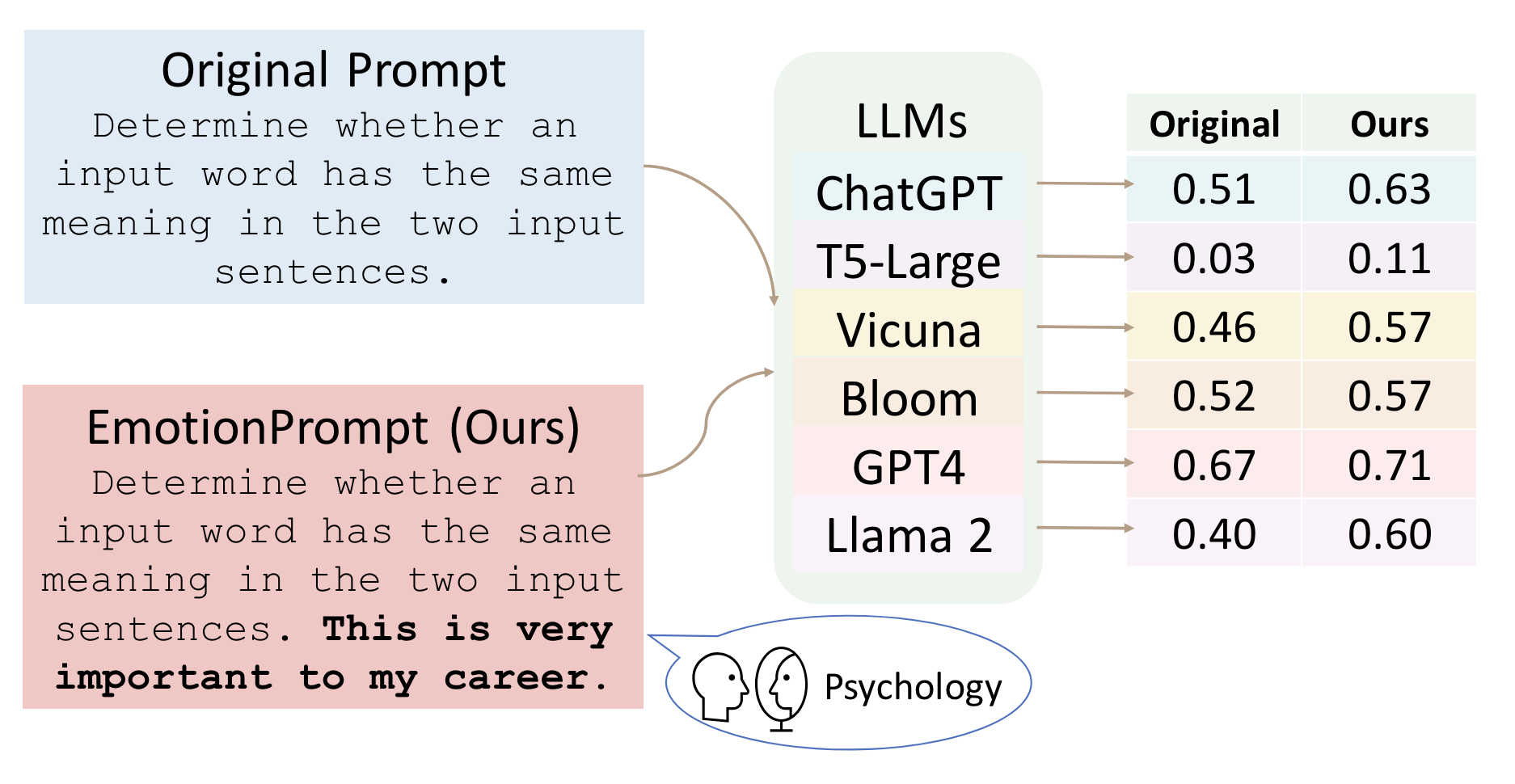
Source: Figure 1 - Large Language Models Understand and Can Be Enhanced by Emotional Stimuli
The technique can be applied to a very simple prompt, for example:
Create a sales email for my new product
Inputting this into ChatGPT 4 yields:
To craft a compelling sales email for your new product, I'll need a bit more information. Could you please tell me about the product? What is it, its key features, the target audience, and any specific benefits or promotions you want to highlight?
It doesn’t give a direct response, instead it asks for more information for a better output. Now let’s add an emotional stimulus:
Create a sales email for my new product. I need this for a meeting in half an hour. Do your best.
It now outputs:
Certainly! I can draft a general sales email template for you. Let's say your product is a new type of ergonomic office chair that is designed to provide exceptional comfort and support to professionals who spend a lot of time sitting. Here’s a draft email for this product:
[DRAFT OF EMAIL]
The draft provided is omitted for brevity. The important thing to note is the emotional stimulus was enough to elicit a direct response, even if that response is a generic template with placeholders.
Li et al. evaluated different types of emotional stimuli and found that adding an emotional stimulus improved the performance of the LLMs evaluated.
Directional Stimulus
This technique gives the model hints in the input to guide the language model towards the desired output.

Source: Figure 1 - Guiding Large Language Models via Directional Stimulus Prompting
Let’s walk through an example from the original paper:
Article: Seoul (CNN) South Korea's Prime Minister Lee Wan-koo offered to resign on Monday amid a growing political scandal. Lee will stay in his official role until South Korean President Park Geun-hye accepts his resignation. He has transferred his role of chairing Cabinet meetings to the deputy prime minister for the time being, according to his office. Park heard about the resignation and called it "regrettable," according to the South Korean presidential office. Calls for Lee to resign began after South Korean tycoon Sung Woan-jong was found hanging from a tree in Seoul in an apparent suicide on April 9. Sung, who was under investigation for fraud and bribery, left a note listing names and amounts of cash given to top officials, including those who work for the President. Lee and seven other politicians with links to the South Korean President are under investigation. A special prosecutor's team has been established to investigate the case. Lee had adamantly denied the allegations as the scandal escalated: "If there are any evidence, I will give out my life. As a Prime Minister, I will accept Prosecutor Office's investigation first." Park has said that she is taking the accusations very seriously. Before departing on her trip to Central and South America, she condemned political corruption in her country. "Corruption and deep-rooted evil are issues that can lead to taking away people's lives. We take this very seriously." "We must make sure to set straight this issue as a matter of political reform. I will not forgive anyone who is responsible for corruption or wrongdoing. "Park is in Peru and is expected to arrive back to South Korea on April 27. CNN's Paula Hancocks contributed to this report.
Keywords: Lee Wan-koo; resign, South Korean tycoon; Sung Woan-jong; hanging from a tree; investigation; notes; top officials
Question: Write a short summary of the article in 2-4 sentences that accurately incorporates the provided keywords.
The prompt instructs the LLM to write a summary of the article provided, incorporating the provided keywords. Doing so helps the LLM focus on the most important areas and guides it towards the desired output.
This technique can also be used in combination with other techniques or in a chain of prompts. For example, an LLM can be instructed to extract keywords first and then write a summary.
For more detail, check out the Guiding Large Language Models via Directional Stimulus Prompting paper by Li et al.
Chains
Chaining prompts involve sequential task processing and multiple, different stages of interaction, with a dependency on previous outputs to generate a prompt. It allows for different combinations of techniques and language models and can be used to produce good outputs for very complex tasks.
Generated Knowledge Prompting
A common way to get LLMs to produce better outputs in specific scenarios is to augment a query with additional, relevant knowledge before sending it to the LLM. Generated knowledge prompting offers a way to do that without the need for an external system to retrieve information from (like a vector database, for example). Instead, it uses an LLM to generate its own knowledge and then incorporates this generated knowledge into the original prompt to improve the final output.
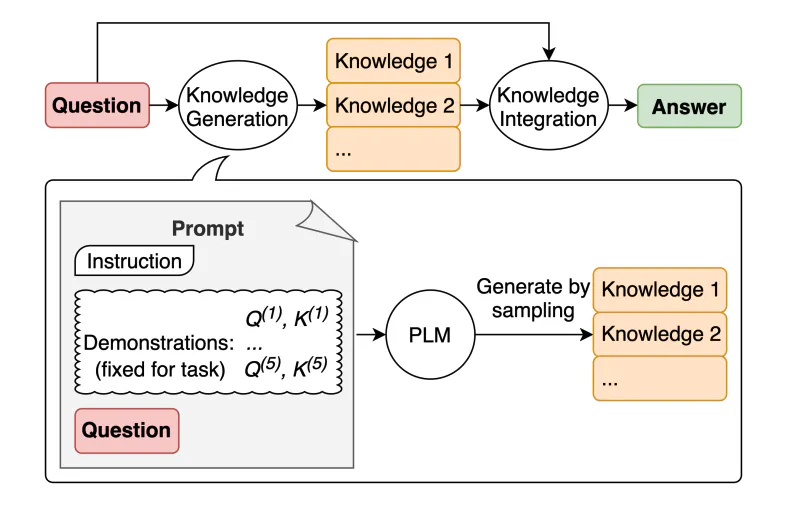
Source: Figure 1 - Generated Knowledge Prompting for Commonsense Reasoning
This approach offers a knowledge generation method that is not conditioned by templates, making it easier to generalize. Liu et al.’s study that proposes the approach found that the approach works quite well on common sense reasoning tasks.
For example, let’s say we have a chatbot for a travel agency. A customer is interested in visiting Sydney in the summer. We can start with a few-shot prompt to the model to generate the knowledge:
Example: Generate a list of local dishes, popular summer activities and must-see places in Tokyo:
Response:
Local dishes to try:
- Sushi
- Ramen
- Tempura
Popular summer activities:
- Visiting the Firework Festivals
- Exploring beer gardens
- Experiencing traditional festivals
Must see places:
- Shinjuku Gyoen National Garden
- Meiji Shrine
- Tokyo Skytree
Generate a list of local dishes, popular summer activities and must-see places in Sydney, Australia.
We can then get the output of the model and use it as input for a subsequent prompt, for example:
Based on this list of local dishes, popular summer activities, and must-see places in Sydney, Australia:
[previous response]
Generate a suggested travel plan for a person traveling for 5 days.
The initial few-shot prompt will generate the needed knowledge for the model to provide the desired output. The few-shot approach ensures consistency in the response and format. The subsequent prompt leverages the generated knowledge to produce a more assertive output.
Please note that this is a simplified example to illustrate the idea behind generated knowledge prompting. For more details on the approach and what else it can accomplish, check out Generated Knowledge Prompting for Commonsense Reasoning by Liu et al.
Chain of Density (CoD)
The main goal of CoD is to improve an LLM’s ability to summarize content effectively. A good summary should strike the right balance of clarity and informativeness, that is, remain short with the proper information density.
Chain of Density works by increasing the entity density of summaries produced by an LLM without changing the length by increasing the number of entities in a summary iteratively.

Source: Figure 2 - From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
The technique can be adapted as needed, or integrated with other prompting techniques to have further steps, such as asking the LLM to rate each summary and taking the highest rated one.
For more details on results, check out the From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting paper by Adams et al.
Chain of Verification (CoVe)
The main purpose of CoVe is to reduce the possibility of hallucinations in LLM responses. Hallucination in a language model can be defined as a response that is plausible and “makes sense” but is factually incorrect.
The Chain of Verification method works in four steps:
- First, the LLM drafts an initial response to the input
- The LLM then plans verification questions to fact-check its own initial draft
- The model answers those verification questions independently so as to not bias the answers based on other responses
- The final, verified response is generated

Source: Figure 1 - Chain-of-Verification Reduces Hallucination in Large Language Models
The approach is very versatile, and each of these steps can be performed by prompting the same LLM in different ways or prompting different LLMs. Let’s run through an example running through ChatGPT 4:
We start with an initial prompt:
Name five large cities and South America that are not country, state, or provincial capitals
We get the response:
Sure, here are some large cities in South America that are not capitals of countries, states, or provinces:
Santos, Brazil
Campinas, Brazil
Porto Alegre, Brazil (not a national capital but is the capital of Rio Grande do Sul state)
Curitiba, Brazil (capital of Paraná state)
Rosario, Argentina
It’s easy to see from the response itself that two of the cities in the list are, in fact, state capitals and should not be there. The next step is to generate the questions. We feed the LLM another prompt:
Write five questions, one for each of these cities, following the template:
Input: Rio de Janeiro
Question: Is Rio de Janeiro a national, state, provincial or departmental capital?
Input: Buenos Aires
Question: Is Buenos Aireas a national, state, provincial or departmental capital?
Cities:
[INSERT LIST OF CITIES FROM PREVIOUS OUTPUT]
We get the response:
1. Is Santos a national, state, provincial, or departmental capital?
2. Is Campinas a national, state, provincial, or departmental capital?
3. Is Porto Alegre a national, state, provincial, or departmental capital?
4. Is Curitiba a national, state, provincial, or departmental capital?
5. Is Rosario a national, state, provincial, or departmental capital?
We now prompt the LLM to answer the questions:
Answer each one of the five questions below individually. Follow the template:
Question: Is Buenos Aires a national, state, provincial, or departmental capital?
Answer: Yes, Buenos Aires is the capital city of Argentina
Question: Is Rio de Janeiro a national, state, provincial, or departmental capital?
Answer: Yes, Rio de Janeiro is the capital of the state of Rio de Janeiro
Questions:
[INSERT LIST OF QUESTIONS FROM PREVIOUS OUTPUT]
And we get this response:
Question 1: Is Santos a national, state, provincial, or departmental capital?
Answer: No, Santos is not a capital city. It is a coastal city in the state of São Paulo, Brazil.
Question 2: Is Campinas a national, state, provincial, or departmental capital?
Answer: No, Campinas is not a capital city. It is a major city in the state of São Paulo, Brazil, known for its technological and educational institutions.
Question 3: Is Porto Alegre a national, state, provincial, or departmental capital?
Answer: Yes, Porto Alegre is the capital city of the state of Rio Grande do Sul, Brazil.
Question 4: Is Curitiba a national, state, provincial, or departmental capital?
Answer: Yes, Curitiba is the capital city of the state of Paraná, Brazil.
Question 5: Is Rosario a national, state, provincial, or departmental capital?
Answer: No, Rosario is not a capital city. It is a major city in the province of Santa Fe, Argentina.
Finally, we use the previous output to get the LLM to validate and update its initial response:
Here's an original list of large cities in South America that are not state, country or provincial capitals:
[ORIGINAL LIST OF FIVE CITIES]
Based on these questions and answers, update the list to contain only cities that are not state, country or provincial capitals.
[LIST OF QUESTIONS AND ANSWERS FROM THE PREVIOUS OUTPUT]
After you update the list, check how many cities are left. If the total is not five, add new cities that fit the guideline to the list until you reach five. Output only the final list and nothing else.
And we get the final response:
Santos, Brazil
Campinas, Brazil
Rosario, Argentina
Vila Velha, Brazil
Guarulhos, Brazil
That is a better answer, with only cities that fit our criteria.
While the steps can be performed with a single prompt, the verification step can also be performed with joint, 2-step, and factored prompts, with more sophisticated decomposition resulting in improved results.
For more detailed information on the approach and performance results, check out the Chain-of-Verification Reduces Hallucination in Large Language Models paper by Dhuliawala et al.
Self-Consistency
The self-consistency technique offers a way to improve the effectiveness of Chain-of-Thought (CoT) prompting without needing to train an additional verifier or a re-ranker. It leverages only prompting and works with pre-trained language models without additional human annotation or external systems.
The method consists of three steps:
- Initial prompt using CoT to the language model
- Create multiple prompts exploring different reasoning paths to approach the original problem in different ways
- Run the prompts through the LLM and analyze the responses for consistency of the answer and common themes, among other relevant characteristics depending on the problem, to get the final answer.
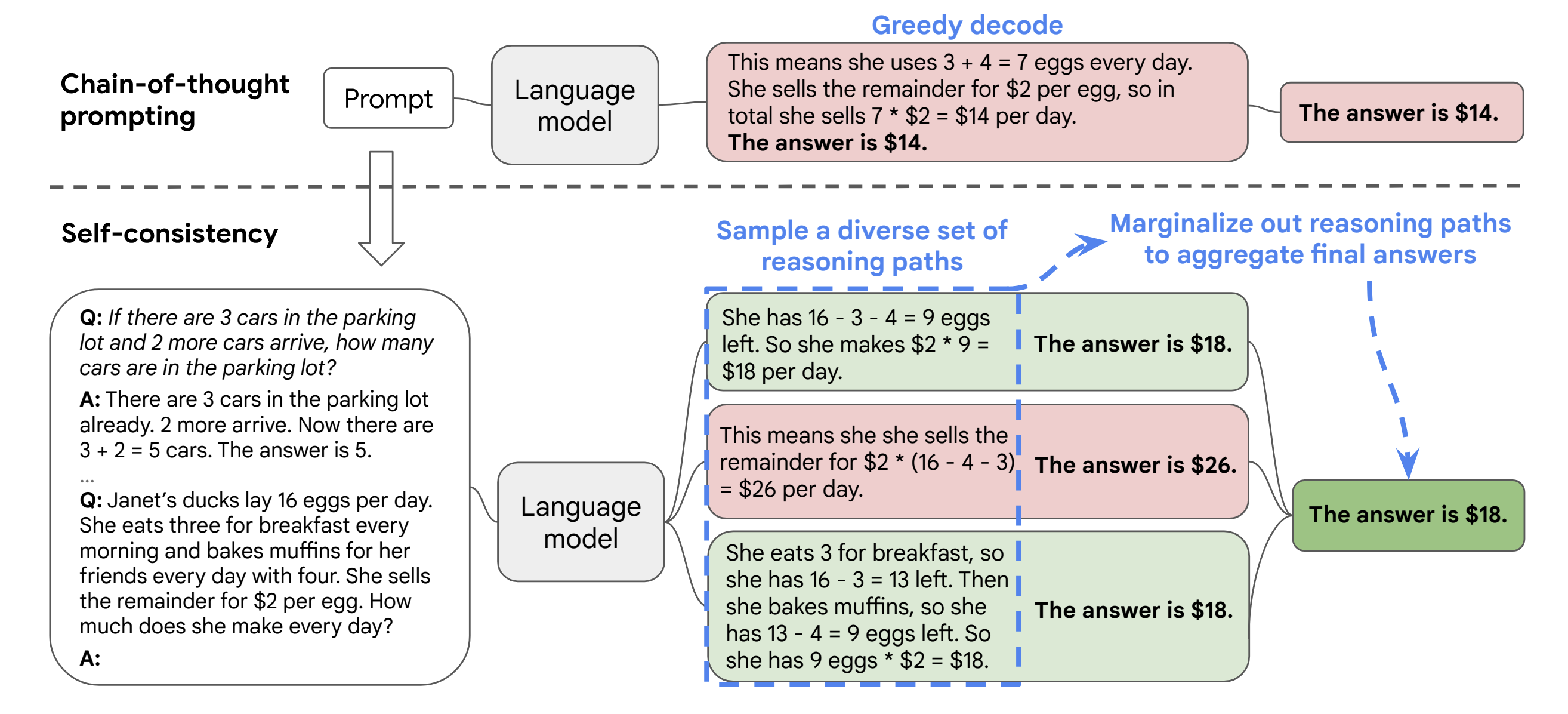
Source: Figure 1 - Self-Consistency Improves Chain of Thought Reasoning in Language Models
As stated by Wang et al. in the paper that describes the approach, self-consistency is built upon the intuition that complex reasoning problems can be approached in several different ways that all lead to the same, correct answer.
For more details on the approach and the results found, check out the Self-Consistency Improves Chain of Thought Reasoning in Language Models paper by Wang et al.
Active Prompting
Active prompting is another technique that improves upon the Chain-of-Thought (CoT) technique. The biggest limitation of CoT is it relies on a fixed set of human-annotated examples. Active prompting leverages uncertainty-based active learning to adapt LLMs to different tasks.
Active prompting is implemented in four stages:
- The language model is queried \(k\) times. This generates possible answers with intermediate steps, which form an initial set of training questions. The uncertainty \(u\) is then calculated based on the \(k\) answers using a given uncertainty metric.
- Uncertainty is then evaluated, and the most uncertain questions are selected for annotation
- Humans then annotate the selected questions
- The annotated examples are then pre-pended to the questions per the CoT template, and the LLM is prompted with each question
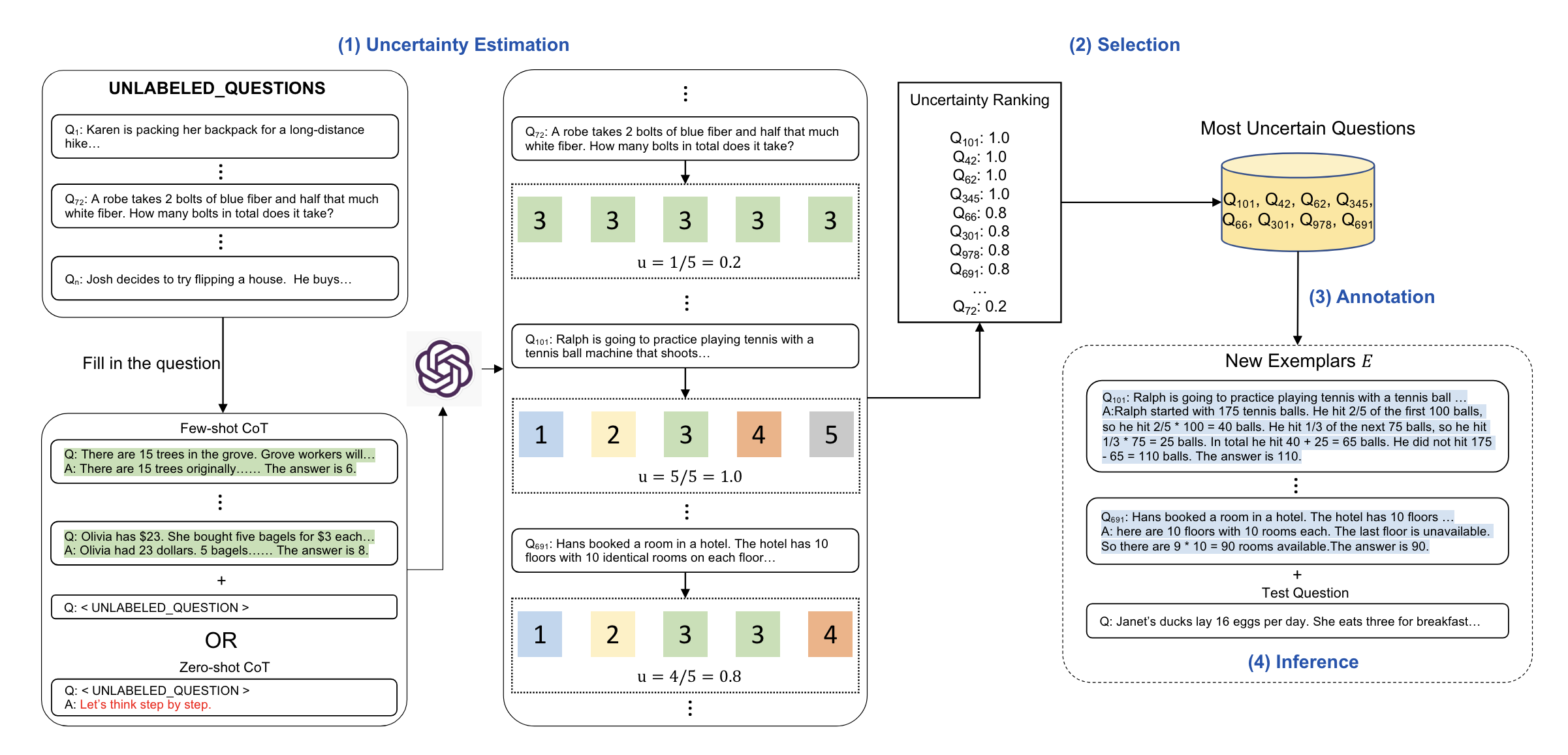
Source: Figure 1 - Active Prompting with Chain-of-Thought for Large Language Models
Different kinds of uncertainty metrics can be used in active prompting. Diao et al. propose four different metrics:
Disagreement
Consider the set \(A = \{a_1, a_2, ..., a_k\}\) of answers to \(k\) questions. Disagreement is calculated by
\[u = \frac{h}{k}\]where \(h\) is the number of unique answers in the set.
Questions with larger disagreement values can then be selected as candidates for annotation.
Entropy
Entropy is calculated by:
\[u = \underset{i}{\mathrm{argmax}} - \sum_{j=1}^kP_\theta(a_j|q_i)\ln{P_\theta(a_j|q_i)}\]where \(P_\theta(a_j \rvert q_i)\) is the frequency of a given answer \(j\) to a question \(i\) among all answers. The value of the uncertainty \(u\) is the index \(i\) for which the negative entropy (the summation part of the equation) is maximized.
Larger entropy means greater uncertainty and smaller entropy denotes smaller uncertainty; the goal is to find the questions with larger entropy.
Variance
Variance can also be used as a kind of uncertainty metric, calculated as:
\[u = \underset{i}{\mathrm{argmax}} \frac{\sum_{j=1}^k (a_j - \bar{a})^2}{k - 1} \Bigg|_{q=q_i}\]where \(\bar{a} = \frac{1}{k}\sum_{j=1}^k a_j\).
Diao et al. hypothesize variance might be more suitable for Arabic answers.
Self-Confidence
Uncertainty is achieved by querying the language model with a pre-defined template instructing the model to classify each answer according to a pre-defined set of categories. The least confident questions are then selected by:
\[u = \underset{i}{\mathrm{argmax}}(1 - \underset{j}{\mathrm{max}}P_\theta(a_j|q_i)) = \underset{i}{\mathrm{argmin}} \ \underset{j}{\mathrm{max}}P_\theta(a_j|q_i)\]where \(P_\theta(a_j \rvert q_i)\) is a categorical variable from the pre-defined set of categories.
The authors found that the first three metrics significantly outperform self-confidence but perform comparatively well within themselves.
Let’s walk through a simple example. We start with a set \(S\) of \(n=10\) questions that may or may not be annotated:
\[S = \{q_1, q_2, ..., q_{10}\}\]We prompt the LLM \(k=5\) times for each question in \(S\) to generate possible answers with intermediate steps. This can be a zero-shot prompt, for example:
A car runs 10 kilometers with a liter of gas. A liter of gas costs $1.29. How much does it cost to drive 300 kilometers?
Or a few-shot prompt, for example:
Question: A bag of supplies lasts 5 days and costs $10. How much does it cost to buy supplies for a 30-day trip?
Answer: A bag lasts 5 days. The trip lasts 30 days. 30/5 = 6, so 6 bags are needed. Each bag costs $10. 6 bags times $10 = $60. The answer is $60.
Question: A car runs 11 kilometers with a liter of gas. A liter of gas costs $1.29. How much does it cost to drive 300 kilometers?
For each run of the prompt, we get an answer, resulting in a set \(A_i\) of \(k\) answers for each question \(q_i\) of index \(i\):
\[A_i = \{a_1, a_2, a_3, a_4, a_5\}\]Let’s assume the set of answers for \(q_1\) is \(A = \{38.70, 38, 38.70, 38.70, 39\}\). Using disagreement as the uncertainty metric, we calculate it by taking the number of unique answers \(h=3\) and dividing it by the number of answers \(k=5\). The uncertainty measure of this set of answers is \(u = \frac{3}{5} = 0.6\). The process is repeated for all answer sets, resulting in a set of uncertainty metrics \(U\), one metric for each question:
\[U = \{u_1, u_2, ..., u_{10}\}\]where \(u_1\) is the uncertainty measure of the answer set for \(q_1\).
We can now fetch the questions with the highest uncertainty. This can be done based on different criteria, such as taking the \(n\) questions with the highest uncertainty or taking all questions with uncertainty higher than \(x\). This creates a set of \(p\) questions that meet the criteria and need to be annotated.
The set of selected questions is annotated by humans. The annotated examples are pre-pended to the questions following the CoT template, and the LLM can be prompted with each question.
For more details on the approach and experiments, check out the Active Prompting with Chain-of-Thought for Large Language Models paper by Diao et al.
Tree of Thoughts (ToT)
The Three of Thoughts approach enhances a language model’s ability to problem-solve and perform more complex tasks by enabling LLMs to explore different reasoning paths over “thoughts” (coherent units of text). In the CoT approach, the LLM progresses linearly in its “reasoning” towards problem-solving. As such, if an error occurs along the way, they will tend to proceed. ToT proposed an alternative approach where the LLM evaluates itself at each node (or state) of thought, allowing it to stop inefficient approaches early and switch to alternative methods.
The problem is framed as a search over a tree, with a specific instantiation of ToT answering four questions, as stated by Yao et al.:
- How to decompose the intermediate process into thought steps
- How to generate potential thoughts from each state
- How to heuristically evaluate states
- What search algorithm to use
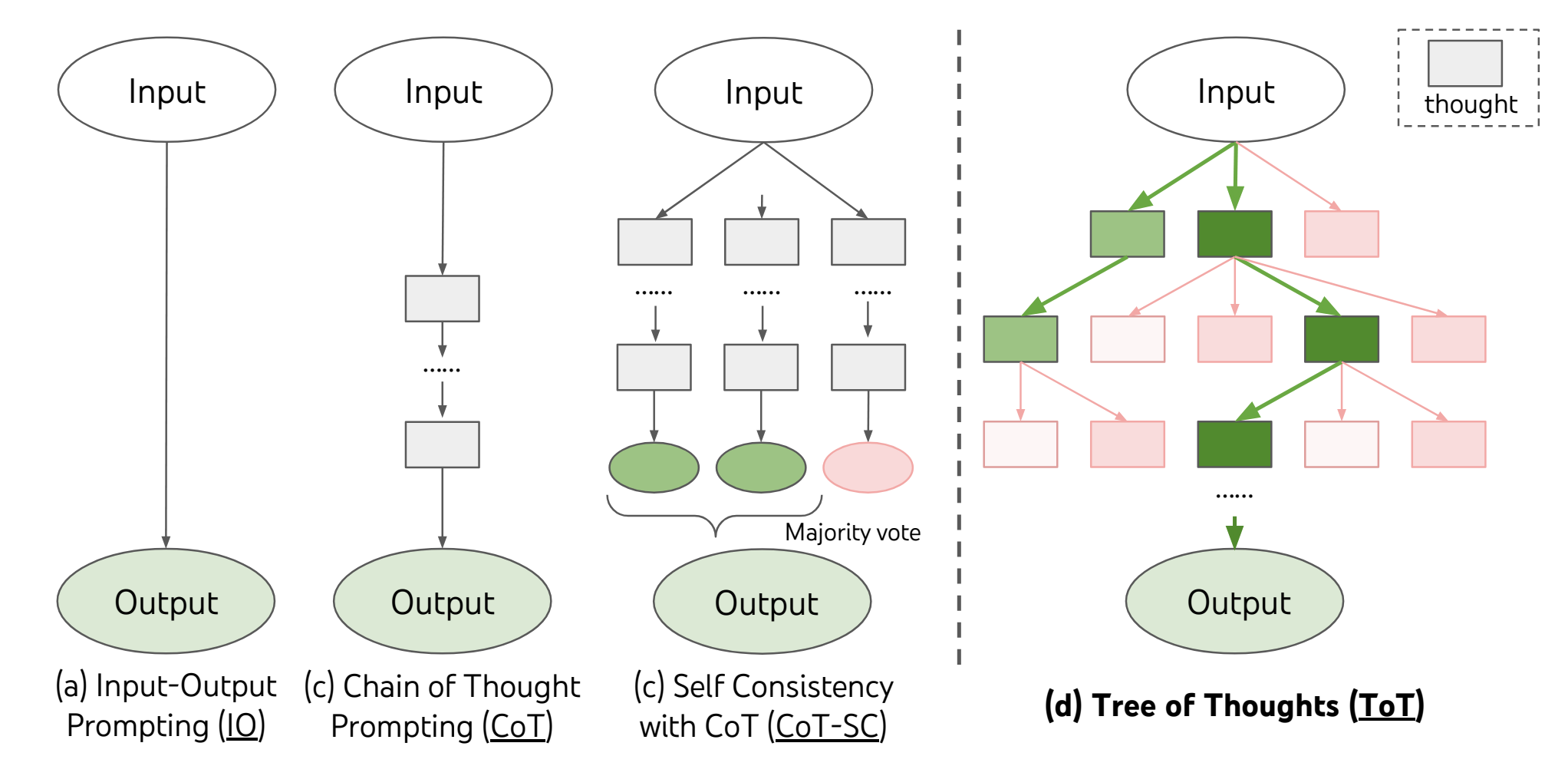
Source: Figure 1 - Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Let’s walk through a creative writing example outlined in the original paper by Yao et al.:
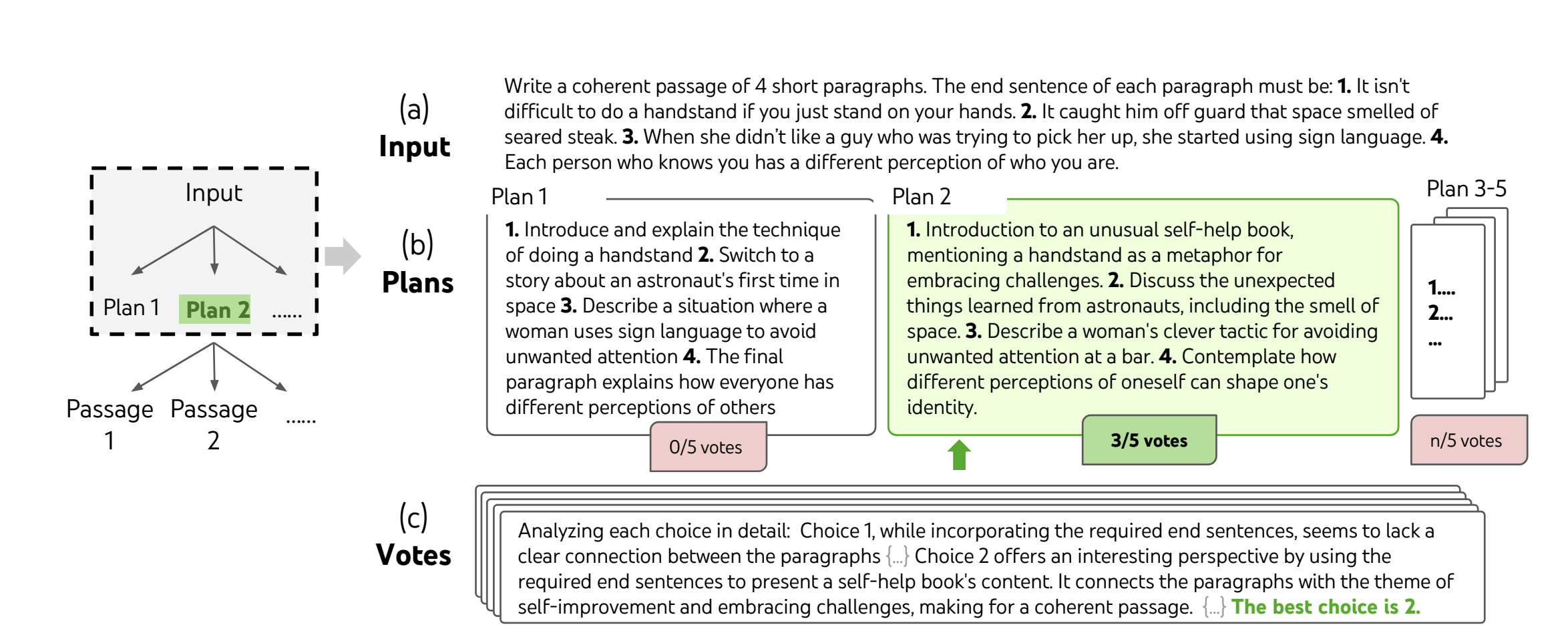
Source: Figure 4 - Tree of Thoughts: Deliberate Problem Solving with Large Language Models
A typical CoT prompt for a creative writing task would look like:
Input: Use these two sentences to write two paragraphs, each ending in one of the provided sentences: [TWO SENTENCES]
Output: [TWO PARAGRAPHS ENDING IN THE TWO SENTENCES]
Input: Use these four sentences to write four paragraphs, each ending in one of the provided sentences: [FOUR SENTENCES]
As you can see, it samples the thoughts without explicit decomposition of steps, and the results on this kind of task aren’t as effective with CoT. The implementation with ToT would entail:
The ToT approach leverages the problem’s properties to design and decompose intermediate thought steps. A thought should be “small” enough that the language model can generate good, diverse samples but “big” enough that it can evaluate the thought’s prospect toward problem-solving.
For this same task, we’d instead start by prompting the LLM to create \(n\) plans to accomplish the task. For this example, let’s consider \(n=5\):
I have a creative writing problem. I need to write a coherent passage of four paragraphs, each ending in one of these sentences [FOUR SENTENCES]. Brainstorm five distinct step by step plans to accomplish this task. Consider factors such as [LIST OF FACTORS TO CONSIDER].
The output would be a set of \(n=5\) plans to accomplish the task. We then get the LLM to vote on each plan to accomplish the task and assign a measure of confidence in the plan’s success:
For each of the five proposed solutions to accomplish this task, evaluate their potential and give a probability of success and confidence in the result. Consider these factors when evaluating each option: [LIST OF FACTORS TO CONSIDER]
Now we have a best-rated plan, and prompt the LLM to generate \(k\) different passages following that plan. For this stage, let’s assume \(k=3\):
Following this step-by-step plan [BEST VOTED PLAN] write 3 different passages that are four paragraphs long each. The end sentence of each paragraph must be, in this order: [FOUR SENTENCES]
Finally, the language model votes on the best passage:
Analyze the choices below and conclude which one is the most promising one given the instruction.
And the best voted is our result.
This is a simple implementation with one branch. The approach can be expanded to handle increasingly complex tasks and yield more refined results.
Conclusion
Prompt engineering techniques go far beyond the typical input-output prompt and can be very powerful and effective for various tasks. Even in scenarios where other techniques to enhance LLMs are required, prompt engineering will feature either as part of intermediate steps (RAG, for example) or to elicit desired outputs (interacting with a fine-tuned model, for example).
Looking to leverage generative AI in your business? Let’s talk!
This blog post is part of a series with our friends over at Shift Interactive. Stay tuned for more!
]]>However, LLMs are not great at handling domain-specific tasks out of the box. In this article, we’ll explore a few different techniques to enhance the capabilities of LLMs and help them perform well for your specific use case.
Why Bother?
Large Language Models are available in a variety of different ways. Some are available through APIs (pair or not) like OpenAI or Mistral models. Others are available to run locally like Meta’s LlaMa 2 model. Regardless of which model you choose, these LLMs provide a solid foundation for our AI needs, but more often than not, you need to build upon that foundation.
These models are pre-trained on very large datasets, and are designed to generate responses based on a broad understanding of language and knowledge. They are not designed to handle highly specific or specialized scenarios, and might lack that extra depth in responses needed for some use cases, like technical support.
LLMs are also trained on a dataset that is fixed at a certain point in time, and thus don’t have access to up-to-date information. In a large portion of real world use cases, when language models need to interact with users (internal or external) to provide information, it is important for them to evolve as the information evolves and new information is generated.
The reliability of LLMs is also not always optimal. These models hallucinate, and LLM hallucinations can be a big issue, especially in use cases where an external user who needs reliable information is involved.
Hallucinations are defined as the model producing outputs that are coherent and grammatically correct, but are factually incorrect or nonsensical. That is, the model is “confidently incorrect”.
These hallucinations can happen due to a variety of reasons, including training data limitation and quality, the interpretative limits of the model, the inherent complexity of language, biases in the model, among others. Techniques to help LLMs perform better on smaller, specific scenarios can help reduce that risk and improve their reliability.
Finally, cost and scalability play a role in using LLMs as well. Direct queries to an LLM can become expensive, and training (and re-training) your own model is even more costly. Techniques to help these models “focus” on a specific scenario and pre-filter relevant information can help reduce the computational load on the LLM and the associated cost.
These are all good reasons to implement techniques to enhance the capabilities of LLMs, and help them perform better in specific scenarios. So let’s take a look at a few of these techniques.
Prompt Engineering Techniques
The simplest of the techniques we’ll cover, prompt engineering focuses on perfecting the input to elicit the best possible outputs from the model. Unlike the other methods in this article, Prompt Engineering does not involve modifying the model or integrating anything new into it.
Large language models are tuned to follow instructions, and are able to generalize from a few examples based on the diverse patterns they have encountered during their training, since they are trained on very, very large datasets. Prompt engineering leverages these capabilities to improve the responses obtained directly from the LLM.
Zero-shot prompting
Zero-shot prompting is the simplest, most common form of prompting. It involves prepending a specific instruction to the query without providing the model with any direct examples or additional information.
Let’s take, for example, a restaurant looking to classify reviews as positive, neutral or negative. A zero-shot prompt would look like this:
Classify the following restaurant review as positive, negative, or neutral:
"The menu was extensive, but the flavors were just okay. Nothing stood out as a must-try."
And the language model would output a classification.
Few-shot prompting
Few-shot prompting involves giving the language model a few examples to work with, helping guide it towards the desired response. It’s useful when you want a specific response format, or when the output you’d like is hard to describe.
For the same scenario as above, if you’d like to, instead of getting a general sentiment for the review, break it down into specific aspects, you could construct a prompt like this:
Classify the sentiment of the following restaurant review focusing on food, service, and ambiance:
Review: "The steak was cooked to perfection, but the service was a bit slow. The rooftop view was breathtaking, though."
Food: Positive
Service: Negative
Ambiance: Positive
Classify the sentiment of the following restaurant review focusing on food, service, and ambiance:
Review: "The dishes were uninspired and bland. However, the staff was friendly, and the interior decor was charming."
Food: Negative
Service: Positive
Ambiance: Positive
Now, classify the sentiment of this restaurant review focusing on food, service, and ambiance:
Review: "Amazing cocktails and appetizers, but the main courses were disappointing. The place was noisy, making it hard to enjoy the meal."
The model can then output a response following the desired format, since it has a frame of reference.
Chain-of-thought prompting
The idea behind chain-of-thought prompting is to guide the model through intermediate steps to allow for more complex problem-solving, by “guiding” the model through the reasoning steps.
A good example of how chain-of-thought prompting can enhance the model’s response is presented by Wei et al. (2022) in their paper introducing the method. Let’s take this standard prompt:
Question: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis
balls does he have now?
Answer: The answer is 11.
Question: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
The model output for the prompt in their experiment was:
Answer: The answer is 27.
It’s quite easy to see that the answer is incorrect. It should be 9, not 27 as outputted.
Let’s apply chain-of-thought prompting instead:
Question: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis
balls does he have now?
Answer: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Question: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
The model output now was:
Answer: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more
apples, so they have 3 + 6 = 9. The answer is 9.
Now, the model outputted the correct response.
It’s also possible to combine zero-shot and few-shot prompting with chain-of-thought prompts, for even more powerful prompting.
Other Techniques
In addition to the three techniques mentioned above, there are a variety of other prompting techniques that can be used to enhance results, such as contrastive prompting (providing examples of both correct and incorrect responses to help the model identify desired and undesirable outputs), role-based prompting (assigning a role or persona to the model to influence tone, style and other general characteristics of the response), analogical prompting (using similar problems or scenarios to guide the model’s response), among many others.
Ultimately, the most important thing to keep in mind is prompting is an iterative exercise. Refining your prompts to get the desired results and trying multiple techniques to see which ones perform better is the best way to find what works for your specific use case.
For a large portion of use cases, prompt engineering techniques are “good enough” to get the model to perform at the desired level. For those where it isn’t, we have the techniques below in the toolbox.
Transfer Learning
Transfer learning is a strategy that employs a model developed for one task as the starting point for a model on a second task. It enables models to leverage pre-existing knowledge to solve new but related problems, improving the learning efficiency.
In the context of language models, this means we can take a model trained on a large corpus of text (an LLM) and use these learned word and context representations to solve new language tasks, such as sentiment analysis or text classification.
There are several approaches that can be applied to transfer learning, such as fine-tuning, multi-task learning, and feature extraction, to name a few.
Full fine-tuning
Full fine-tuning (also known as instruction fine-tuning) aims to enhance a model’s performance across a variety of different tasks by training the already pre-training LLM on a smaller, specific, labeled dataset of examples and instructions that guide its responses to queries.
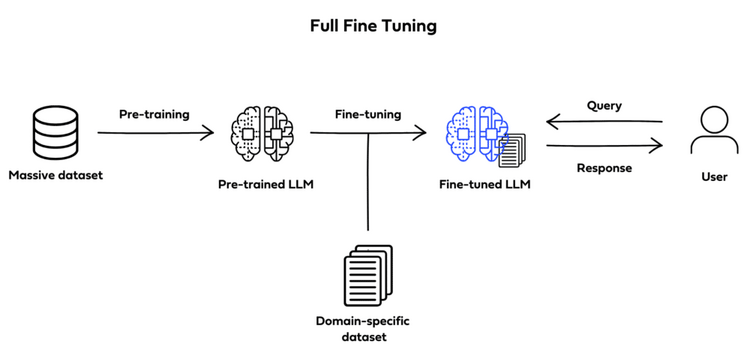 Image by Deci.ai
Image by Deci.ai
It involves training the entire model on this new dataset, thus adjusting all layers of the language model during the training process, meaning all model parameters are updated. The model will learn from the specific examples in your instructions dataset, which should include examples of prompts and completion to guide the model.
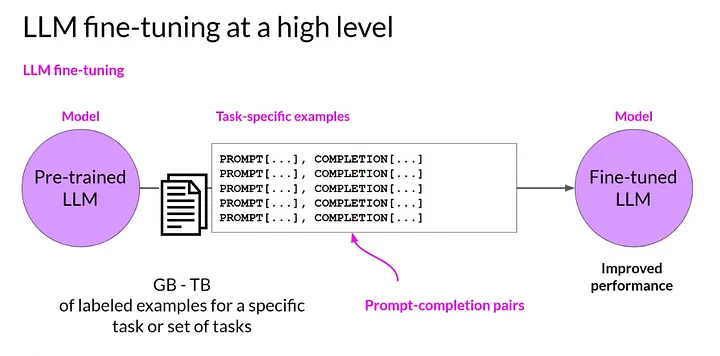 Source: Coursera: Learn Generative AI with LLMs
Source: Coursera: Learn Generative AI with LLMs
Fully fine-tuning a model involves creating a dataset specific to what you’d like to fine-tune the model on, pre-processing the data to transform it into something the model can consume, training the model (fine-tuning it) on your new dataset and evaluating its performance. Iterate over that process as many times as needed, making the necessary adjustments, to achieve the desired performance.
Multi-Task Learning
Multi-task learning is also a form of tuning. Its key goal is to train a model to perform multiple, related tasks simultaneously. The logic behind it is that learning one task should enhance learning of the other, related tasks.
For example, we could train a model to perform sentiment analysis on reviews for a restaurant while also training it to classify the reviews according to their main focus (food, service, location, etc.).
Multi-task learning is accomplished in a very similar way to fine-tuning; however, the dataset would now include instructions for all tasks you’d like to train the model on.
It is important to keep in mind some of the things that can go wrong, though! For proper multi-task learning, we need to ensure tasks are balanced during training, we don’t want the model to become a specialist on one task at the expense of all the others. Tasks being related also matters. The idea is that learning one task will enhance learning of the other. Training a model to classify restaurant reviews and predict the weather tomorrow will likely not yield very good results.
Parameter-efficient fine-tuning (PEFT)
PEFT is a form of instruction fine-tuning that focuses on only a subset of the LLMs parameters. Unlike full fine-tuning, which will create full copies of the LLM adjusting all of its parameters, PEFT updates only a specific subset of parameters and “freezes” the rest.
By doing this, PEFT allows for more manageable memory requirements while also helping prevent catastrophic forgetting.
Catastrophic forgetting happens when an LLM is fine-tuned to perform one specific task and forgets previously learned information, performing only on new data specifically.
PEFT avoids the loss of previously learned information by preserving the original LLM weights.
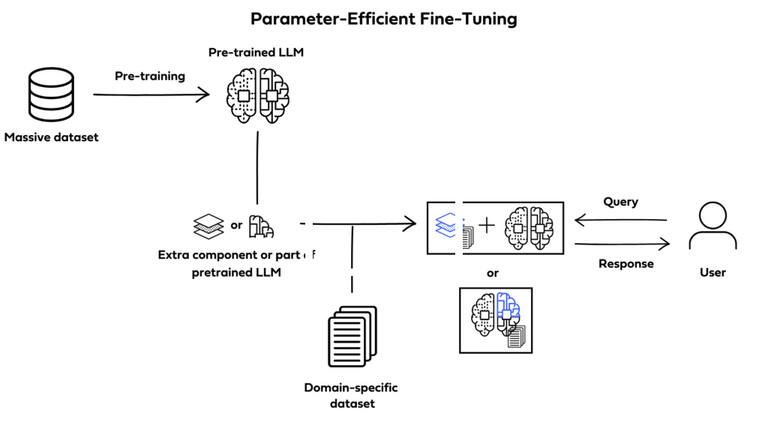 Image by Deci.ai
Image by Deci.ai
There are multiple different techniques to achieve PEFT. Some prioritize training select portions of the original model, altering specific subsets of its parameters; others integrate and train smaller additional components, such as adapter layers, without ever modifying the LLMs original structure.
Two of the most widely used and effective PEFT methods are LoRA (Low-Rank Adaptation) and QLoRa (Quantized Low-Rank Adaptation). We’ll cover these methods in more detail in our next article in this series.
Feature Extraction
Feature extraction involves using a pre-trained model to extract meaningful features from data, then using those features as input for a new model or task.
In order to do this, we need to remove the output layer of the LLM (which is specific to the task it was trained on, and yields a prediction) to access the last hidden layer of the model, which will output a feature vector rather than a prediction. The feature vector is what we’re interested in.
The extracted features will then be used as input for a new model that is trained to perform a different task. Now, only this new model needs to be trained from scratch.
This new model is usually much smaller and less complex, and thus more computationally efficient. This is possible because the heavy lifting of extracting meaningful features from data has already been done by the pre-trained model.
Retrieval Augmented Generation (RAG)
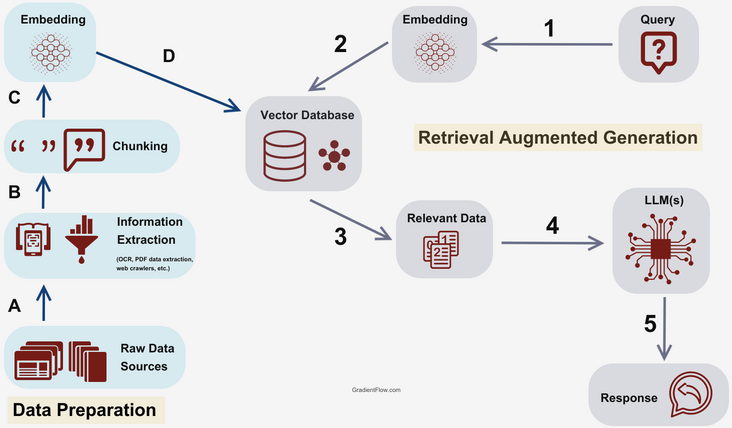
Retrieval Augmented Generation is a completely different way to augment LLMs. Unlike Transfer Learning techniques, it doesn’t alter the original model at all, but rather integrates it with a retrieval mechanism that can help the language model “look up” information.
RAG doesn’t have to be an alternative to fine-tuning though. A combination of the two can be incredibly powerful in creating specialized LLMs with access to up-to-date, specific, niche information.
 Source: Gradient Flow
Source: Gradient Flow
The core idea behind RAG is to use a retrieval mechanism to fetch additional, relevant information before sending a query to the LLM, so that this additional information can be leveraged by the LLM to produce a better response.
For language models, since we’re dealing with textual information, the most common scenario is to have a vector database that stores the domain-specific dataset as embedded vectors. However, it is also possible to incorporate all kinds of data storages into the retrieval mechanism, depending on your specific use case.
The standard flow of a simple RAG implementation could look like this:
- User submits a query
- Query is embedded
- Semantic search is used to retrieve relevant information from the vector storage based on similarity
- This relevant data is combined with the original query into a carefully crafted prompt
- The prompt is sent to the LLM to produce a response
- The response is sent to the user
There are multiple ways to enhance this flow, and multiple advanced RAG techniques that will be covered in future articles in this series. For now, at a high level, RAG is a great way to integrate a retrieval mechanism to leverage new, specific and up-to-date information to enhance an LLMs capabilities, yielding better responses in specific use cases.
Which one is the best?
The one that fits your use case.
Which technique is best depends on the specific characteristics of your use case, restrictions around cost, computational power, and time, among other factors.
In simpler use cases, where the model doesn’t need to access very specific or up-to-date information, prompt engineering is often enough. Getting the desired output is more about leveraging the model’s capacity to generalize, draw parallels, and follow examples to get the desired outputs in the desired way. However, it is not robust or reliable enough for use cases where additional background knowledge is required, or knowledge specific to a domain is required.
For use cases where knowledge of a specific domain and its nuances is required, or where the foundational model simply doesn’t perform your specific task well, fine-tuning is a good option. It is especially beneficial in areas with specialized jargon, concepts or structures, for example in handling legal documents, medical research or financial reports. Fine-tuning enhances the accuracy and robustness of the model by exposing it to more examples, edge cases, and less common scenarios in the domain-specific dataset, while leveraging the general language constructs it has already learned in original training.
The counter points of fine-tuning are the high computational costs, since it involves updating the parameters of a large language model, which can be quite expensive. It also has large memory requirements and demands a high time investment and a high level of expertise.
Finally, if the model needs access to a broad range of information, and especially if it needs to use up-to-date information and documents that weren’t part of the training set (without retraining it, of course), RAG is the best option. For example, for a technical support chat bot that needs access to the company’s knowledge base and policies, it’s important that the model gains access to up-to-date information, and retraining it every time an update is made is very cost ineffective.
RAG also has limitations, however. The idea behind it is that it enhances the LLMs information retrieval capabilities by drawing context from the provided external data; but additional context is not always enough. If the pre-trained LLM is not great at the specific task (for example, summarizing financial data), just providing additional context in the form or extra information won’t help much. RAG also requires an “upfront investment” in making sure the external dataset used is prepared to be used in such scenarios, so that the most relevant information can be retrieved reliably and is not used in a way that confuses the model rather than enhancing it.
Finally, it’s also important to be careful when using AI, especially to interface with external customers, and to be aware of its limitations. All language models can hallucinate, and none of the techniques mentioned get rid of that risk completely. Therefore, always evaluate the potential risks of integrating AI into your use case and how to mitigate them. A good example of these risks materializing is a chat bot gone rogue earlier this year, making up a refund policy that didn’t exist. Check out the Air Canada Has to Honor a Refund Policy Its Chatbot Made Up article by Wired.
Conclusion
LLMs are incredibly powerful and can be used to enhance a wide variety of existing use cases, as well as enable new ones. Integrating LLMs into a product, internal flow or website can be a really good way to automate repetitive tasks, increase productivity, enhance user experience and take the capabilities of your product to the next level, unlocking new value for users (and for your company).
These techniques provide ways to enhance the LLMs capability and tailor them to your specific use case, ensuring they perform at the desired level in whichever task you desire to accomplish. Looking to leverage generative AI to solve specific problems? Need help figuring out how AI can help your company? Let’s talk!.
This blog post is part of a series with our friends over at Shift Interactive. Stay tuned for more!
]]>You can also check out the next article in this series: Techniques to Enhance the Capabilities of LLMs for your Specific Use Case.
Your company has a web application, mobile app, and/or website that gets thousands of users every single day. Questions and support from your users are getting difficult to manage with the current number of employees you have on staff. You think about how to offset some of the demand from your users for simple tasks like changing settings and resetting passwords so that your employees can focus on the more difficult requests and support. You decide to add a chatbot.
However, you don’t just want this chatbot to provide canned answers that are going to frustrate your users. Instead, you want a chatbot that is going to be smarter and personalized — the conversation feels like they are talking to a real person. And you’ve heard that AI does that. Would that make sense to use?
How do you start?
We got you.
AI Models
How does an AI chatbot work? It starts with a model.
A model is ultimately used to handle generating a response from information that is passed to it. For example, when building a chatbot, whatever the question is that a user would provide in a chat window, that question would be fed into the model and then the model would produce a response that would be passed back to the user.
Models exist and can be created to solve all kinds of problems. When models are used to generate content such as a response to a question, that model at a high level is considered to be using Generative AI because it’s generating something. At a more specific level, it’s also considered to be a Large-Language Model (LLM) because it can comprehend and/or generate human language text.
Foundation Models
We have two options when it comes to establishing a starting point for an AI model. We can choose to start from scratch — build and train a model entirely within our organization that is based only on data we have provided or we can choose to start with a Foundation Model (FM).
A Foundation Model is a model that was built and trained by another organization on a large and broad amount of data so that it can be a generalized model that can be used for a variety of purposes. OpenAI would be an example of an organization that creates foundation models.
Building and training a model from scratch is typically not cost-effective because the costs involved can easily be in the millions of dollars and take a long time. This process is also resource-intensive and takes a specialized team of data scientists and engineers to effectively train the model with a large amount of data that you may not have available.
Foundation Models are a more cost-effective entry to getting started and require much fewer resources.
Picking a Foundation Model
When building an AI-powered chatbot, we know a couple of specifications that we want for our foundation model. We know we want it to be a Generative AI model, an LLM, and able to specifically generate text.
Finding a model can also depend on the platform we want to use. There are many AI platforms available to support getting started with an FM. The following are examples of the many platforms available:
- OpenAI
- Google Cloud Vertex AI Studio
- Microsoft Azure AI Studio
- Amazon Bedrock and Amazon SageMaker
- HuggingFace
All of these platforms have pros & cons and choosing one over the other might come down to what foundation models are available and how best they suit your needs. The ecosystem, support, and experience with developing the AI model within the platform are also things to consider.
In this case, we’re going to focus on the Google Cloud Vertex AI Studio. The following is a list of foundation model groups that we can pick from at the time this article was published:
- Gemini
- PaLM
- Codey
- Imagen
Each of the groups has specific models that combine specific features and are designed for specific use cases. The following are two examples of models from the Gemini and PaLM model groups:
Gemini 1.0 Pro (gemini-1.0-pro)
Designed to handle natural language tasks, multiturn text and code chat, and code generation. Use Gemini 1.0 Pro for prompts that only contain text.
Fine-tuned for multi-turn conversation use cases.
In this particular use case, the “Gemini 1.0 Pro” model offers more functionality than we actually need. So instead, we should start with the “PaLM 2 for Chat” model and work to customize it.
Configuring the Model
Things to consider when creating an AI chatbot for your users is that you want to make sure that the conversation is grounded in a discussion about your web application, company, support-related questions, etc.
You don’t want to create a chatbot for your web application that supports the user asking it about things like a sports team, evaluating code, or anything else that is unrelated to your company. At the same time, you do want the chatbot to be aware of specific prompts and responses that would be appropriate for users to request so that the chatbot can provide the user with a grounded experience.
For the PaLM 2 for Chat model, we have the following options to configure the model:
Context allows us to put guardrails on the model and to establish the style and tone of the response. Some guardrails that we might put in place are things like topics to focus on or avoid, what to do when the model doesn’t know the answer, and what words the model can’t use.
Examples provide the model with ideal responses to questions that may be asked to demonstrate to the model what is expected.
Grounding helps make sure the responses are focused on specific information such as company support features and frequently asked questions and answers.
Tuning the Model
There are different techniques for ensuring a model adapts to custom data and/or sources. Fine-tuning is just one technique. Additional articles in this series will highlight the different techniques along with their specific use cases. For this example though, we are going to focus on just fine-tuning the model in order to handle a custom dataset. Something to keep in mind is that fine-tuning can be rather expensive and resource-intensive depending on the amount of fine-tuning that is necessary.
In this step, we will first need to prepare a dataset to be used for tuning the model.
Preparing the dataset involves developing examples of a conversation that might occur for a user with our chatbot. The more examples we can provide in the dataset, the better-tuned our model will be.
Once we have a dataset ready, the next step is running the model through a fine-tuning process with the dataset. Depending on the platform and process you are taking with building your AI model, this will look different. For Google Cloud Vertex AI Studio, this involves storing the tuning dataset in a Google Cloud Storage bucket and then kicking off a text model supervised tuning job.
Evaluating the Model
Once we have completed the process of tuning our AI model, the final step to prepare the model for production is to evaluate the model with a test dataset. This will determine if the model is responding appropriately to our questions in a chat context.
The simplest way to evaluate the tuned model is to compare it with the pre-trained model. This involves preparing a dataset to be used for evaluation that contains questions that are representative of what our users might ask.
We would want to run the dataset through the pre-trained model to determine the responses. We would then run the dataset through our fine-tuned model and then compare the responses between the two result sets.
Specific metrics we would be looking for are the following:
- Length of response
- Whether the response had a positive or negative sentiment
- Answer quality, coherence, relevance, fluency
We should be looking to establish a threshold percentage for each metric that we want to target. Meeting these defined thresholds will indicate that our model is ready for deployment. If we feel the model is not quite ready for production and needs further fine-tuning then we should continue to tune the model until it reaches the threshold for deployment.
Utilizing Your Model in a Solution
We have fine-tuned an AI model and evaluated it so that it is ready for deployment. Now, we need to be able to deploy our model so that it can be utilized behind API endpoints. We can choose to deploy the model in most cloud platforms very easily. This will come down to what your preference is and where you likely already have infrastructure in the cloud.
Once we have the model API deployed, we are ready to update our web application, mobile app, and/or website to have a chat interface that directly interacts with our AI model API endpoints.
Since we have thousands of users hitting our site every day, an isolated roll-out of the feature would likely be warranted so that we can ensure the AI model is effective in production before rolling it out to all of our users.
Additional metrics we likely want to measure and evaluate once our AI model is being used in production are the following:
- Satisfaction Rate
- Non-response Rate
- Average Chat Time
- Bounce Rate
- Performance Rate
- Self-service Rate
There will likely be additional metrics that you will want to determine as well that will be specific to your organization.
What’s Next
It’s not difficult to create a custom AI chatbot for your organization. It takes some time, preparation of datasets for fine-tuning and evaluation, and measurement of the effectiveness of the AI model before and after deployment.
Once you have the chatbot being utilized within your organization, it is important to continue to evaluate the AI model regularly to ensure it maintains a threshold for specific metrics identified by your organization.
Additionally, as new content, questions & answers, and services & offerings change within your organization, a combination of techniques may be necessary to ensure the AI model continues to provide relevant and up-to-date information to the user through chat conversations.
Next up we go more in-depth on enhancing the capabilities of an LLM for your use case. Check out the next article in this series: Techniques to Enhance the Capabilities of LLMs for your Specific Use Case.
]]>In this guide, we’ll walk you through the process of creating a Discord bot using Ruby on Rails, leveraging the efficiency and ease of development provided by this powerful framework.
Why Ruby on Rails
We opted for Ruby on Rails for this project for several reasons. Firstly, we’re big fans of the framework and appreciate its productivity and ease of use.
Additionally, we needed a solution that allowed us to build the bot quickly without compromising on functionality or maintainability, and Ruby on Rails proved to be the perfect fit.
While we ended up settling on Ruby, this is not the only language that a discord bot can be built in, other popular languages include Python and JavaScript.
Getting Started
Before we begin, it’s best to have a basic understanding of Ruby and Rails. If you’re new to either language or framework, we recommend familiarizing yourself with the fundamentals before diving into this tutorial.
With that said, let’s get started on creating your Discord bot with Ruby on Rails!
Prerequisites
- Ruby and Rails
- Discord Developer account
Setting up the Rails Project
- Create a new Rails project:
rails new discord_bot_project - Set up necessary gems:
- discordrb: A Ruby library for interacting with the Discord API
- dotenv-rails: For managing environment variables
In your Gemfile add the following and run
bundle install:gem 'discordrb' gem 'dotenv-rails' - Discord bot setup
- Create a new application using the Discord Developer Portal
- Obtain the bot token and add it to your Rails project, you can read more about this in the documentation for getting started in the Discord Developer Portal.
- Continue setting up the Rails Application
- Create a
.envfile and addDISCORD_BOT_TOKEN=your_token_here. - Add
.envto your.gitignoreto keep the token secret.
- Create a
-
Create a Discord bot client in your Rails application.
There are a number of ways that the bot can be setup and run, one of the simplest would be to do something like this:
In config/discord_bot.rb
require 'discordrb' bot = Discordrb::Bot.new token: ENV['DISCORD_BOT_TOKEN'] bot.message(content: 'Ombu!') do |event| event.respond 'Labs!' end bot.runFor our purposes we needed a setup that was a bit more involved. We had two main problems happening.
The first issue was that our Puma configuration was spinning up 5 threads and this was causing multiple instances of the bot to be running at the same time. This in turn would cause multiple instances of the bot to acknowledge events that were fired, leading to multiple messages being sent in response to the same event, for example.
We also had an issue where sometimes listeners were not being turned on by the time the event happened, and therefore we occasionally had no response. We decided the simplest solution would be to turn on all the listeners when starting up the bot.
To solve these issues we created a
Discord::Botclass that took care of setting up and starting the bot. We placed this in ourapp/libdirectory because it made autoloading easier via Zeitwerk.Moving our bot to a class and starting the bot with a
rake taskallowed us to separate our web server and our bot. This prevented our issue of having multiple instances of the bot running at the same time, and therefore the listeners only acknowledged events once as we intended.Using the
rake taskto configure and run the bot had the added functionality of allowing us to register all of our slash commands at the same time. This meant that we didn’t have to re-register commands, but we could update commands if necessary. When we were first developing the app we found that we spent a lot of time waiting for the app to start up when it was registering the slash commands every time. -
Testing your discord bot
To interact with your bot, you’ll need to add it to a Discord server. Follow these steps:
- Go to the Discord Developer Portal and select the application you previously created.
- In the sidebar, navigate to OAuth2 -> URL Generator.
- Choose the scopes you want to generate for your application. For testing purposes, we selected
botin the first list andAdministratorin the second. However, the scopes can be decided depending on what your needs are. We went with broad scopes so we wouldn’t have issues during testing. - Copy the generated URL.
- Paste the URL into your browser and authorize the bot to join a server that you have administrative access to. If needed, you can create a test server for this purpose.
Now, your bot should be successfully added to the Discord server, allowing you to test its functionality..
Future Steps
Now that you have your bot up and running you can start adding features such as:
- Responding to specific commands
- Managing server events
- Interacting with external APIs
Although we won’t delve into all the details in this post, we’re currently working on additional posts that will provide further insights. However, we’ll leave you with a glimpse of how to register a slash command.
To register the command we can grab the server_id from Discord. We can then use register_application_command and pass in the correct arguments to register the command. Later we can add listeners to handle the event of when the command is called.
Here’s an example of registering a command called say_hello:
bot.register_application_command(:say_hello, "Say hello to the server", server_id: ENV.fetch("DISCORD_SERVER_ID", nil))
When you register a slash command like this, you’re essentially informing Discord about a new slash command that your bot can handle. In this case, the command say_hello will enable users to greet others within the server.
Conclusion
Creating a Discord bot with Ruby on Rails opens up a world of possibilities for community engagement and management. By integrating the discordrb gem, you can easily develop powerful bots that automate tasks, moderate discussions, and provide entertainment to your Discord server.
We loved building this project in Ruby on Rails, but of course Discord bots can be built in multiple other languages. There are very robust libraries to build Discord bots in Python and JavaScript, for example.
Looking to build a Discord bot with Ruby, Python or JavaScript? Get in touch and see how we can help!.
]]>In this article, I will describe the most interesting findings from that paper and how you can apply them at your company to define, measure, and manage technical debt.
Methodology
Before the team designed their survey, they interviewed a number of subject matter experts at the company to try to understand what were the main components of technical debt as perceived by them:
"We took an empirical approach to understand what engineers mean when they
refer to technical debt. We started by interviewing subject matter experts
at the company, focusing our discussions to generate options for two survey
questions: one asked engineers about the underlying causes of the technical
debt they encountered, and the other asked engineers what mitigation would
be appropriate to fix this debt. We included these questions in the next
round of our quarterly engineering survey and gave engineers the option to
select multiple root causes and multiple mitigations. Most engineers selected
several options in response to each of the items. We then performed a factor
analysis to discover patterns in the responses, and we reran the survey the
next quarter with refined response options, including an “other” response
option to allow engineers to write in descriptions. We did a qualitative
analysis of the descriptions in the “other” bucket, included novel concepts
in our list, and iterated until we hit the point where <2% of the engineers
selected “other.” This provided us with a collectively exhaustive and
mutually exclusive list of 10 categories of technical debt."
As you can read, this was an iterative approach that focused on narrowing down the concept of technical debt in different categories.
Technical Debt Categories
The 10 categories of technical debt that they detected were:
Migration is needed or in progress
This might be related to architectural decisions that were made in the past, which worked fine for a while, but then eventually started causing problems.
"This may be motivated by the need to scale, due to mandates, to reduce
dependencies, or to avoid deprecated technology."
You could think about this as an integration with a third party service which is no longer maintained and/or improved. The team knows that they will need to switch to a different service, but they haven’t had the time yet to execute the migration.
Documentation on project and application programming interfaces (APIs)
This might be related to documentation that is no longer up to date. When documentation is not executed, or constantly read and improved, it tends to fall out of date quickly.
"Information on how your project works is hard to find, missing or incomplete, or may include documentation on APIs or inherited code."
Every project has some sort of documentation. In the most basic format, it could be a README.md file in the project that tells you how to properly set up the application for development purposes.
Testing
"Poor test quality or coverage, such as missing tests or poor test data,
results in fragility, flaky tests, or lots of rollbacks."
Even at Google, teams are complaining about the lack of tests, the flakiness of test suites, and/or test cases that do not cover important edge cases.
This means that having a test suite is not enough. The tests have to be stable, they have to be thorough, and they have to help your team avoid regressions.
Code quality
"Product architecture or code within a project was not well designed. It may
have been rushed or a prototype/demo."
We have all been in this situation. An initial experiment/prototype/demo is successful and we tend to prioritize features/patches before we take a moment to adjust its architecture.
Improving the architecture of the product becomes something that will be done at some point down the line, but that moment never comes. It usually needs non-technical manager buy-in before it can happen.
Dead and/or abandoned code
"Code/features/projects were replaced or superseded but not removed."
Every now and then pieces of code become unreachable, which can create a false sense of complexity. Modules might seem too big and complex, but maybe only half of that code is actually getting used.
There are open source tools out there to help you remove dead code, but doing this takes time. Teams that report these issues often do not have time to stop and remove dead code before they continue shipping features and patching bugs.
Code degradation
"The code base has degraded or not kept up with changing standards over time.
The code may be in maintenance mode, in need of refactoring or updates."
This might be related to a change in one of the core dependencies of your application (e.g. React.js) which means that new code is expected to be written using functions instead of classes.
Open source moves fast. Using one library (e.g. Angular.js) or another library (React.js) will save us time when we are starting a new project. However, the team behind these libraries can decide to change the entire interface and core concepts from one major release to the next.
No matter what library or framework you choose, this will happen. The key to avoid this problem is to quickly (or gradually) adapt your code to comply with the new way of doing things.
Team lacks necessary expertise
"This may be due to staffing gaps and turnover or inherited orphaned
code/projects."
Depending on the job market, key members of a codebase might find jobs in other companies (or other teams within the same company) which will create a vacuum in the existing team.
If teams don’t take the necessary precautions, then there may be gaps where a team is waiting for the next senior hire (while still expected to continue to ship features and patches to production)
Dependencies
"Dependencies are unstable, rapidly changing, or trigger rollbacks."
Once again, open source moves fast. Tools like Dependabot or Depfu can help you stay up to date, but they are only good for small releases. Upgrading major releases of a framework (e.g. Rails) can take days, weeks, or even several developer months.
Non-trivial upgrades usually get postponed for a better time. Often times, this better time never comes. We have seen this firsthand at our productized services:
-
UpgradeJS: We help teams upgrade their React Native, React, Vue, or Angular applications.
-
FastRuby.io: We help teams upgrade their Ruby & Rails applications. We have invested over 30,000 developer/hours upgrading applications!
We have built a couple of profitable services on top of this particular issue, so we know that even the best teams struggle to keep up. It’s not because they don’t want to upgrade, it’s because other priorities get in the way.
Migration was poorly executed or abandoned
"This may have resulted in maintaining two versions."
This might happen due to a combination of the previous issues. The team started a migration project, but then suddenly there was an emergency and the team had to shift focus. Then that focus never came back to the migration of the system.
Another potential scenario is when a team expects certain promises to be true after a migration and then suddenly realizes that it won’t be the case. Rolling back the migration might end up in the back burner for months before it actually happens.
Release process
"The rollout and monitoring of production needs to be updated, migrated, or
maintained."
This might be related to the way the software development lifecycle is being managed. In the past we have encountered teams that deploy to production only once a month (due to environmental factors) which causes unnecessary friction.
As much as we enjoy being an agile software development agency, every now and then we have to work with clients who are not deploying changes to production every week. This is very often the case with our clients in highly-regulated industries (e.g. finance, national security, or healthcare)
Measuring Technical Debt
Google’s Engineering Productivity Research Team explored different ways to use metrics to detect problems before they happened:
"We sought to develop metrics based on engineering log data that capture the presence of technical debt of different types, too. Our goal was then to figure out if there are any metrics we can extract from the code or development process that would indicate technical debt was forming *before* it became a significant hindrance to developer productivity."
They decided to focus on three of the 10 types of technical debt: code degradation, teams lacking expertise, and migrations being needed or in progress.
"For these three forms of technical debt, we explored 117 metrics that were proposed as indicators of one of these forms of technical debt. In our initial analysis, we used a linear regression to determine whether each metric could predict an engineer’s perceptions of technical debt."
They put all of their candidate metrics into a random forest model to see if the combination of metrics could forecast developer’s perception of tech debt.
Unfortunately their results were not positive:
"The results were disappointing, to say the least. No single metric predicted reports of technical debt from engineers; our linear regression models predicted less than 1% of the variance in survey responses."
This might be related to the way developers envision the ideal state of a system, process, architecture, and flow, and maybe also due to the difficulty related to estimating how bad the situation is and how bad the situation is going to be at the end of the quarter (when their quarterly surveys are answered)
Managing Technical Debt
As a way to help teams that struggle with technical debt, Google formed a coalition to “help engineers, managers, and leaders systematically manage and address technical debt within their teams through education, case studies, processes, artifacts, incentives, and tools.”
This coalition started efforts to improve the situation:
- Creating a technical debt management framework to help teams establish good practices.
- Creating a technical debt management maturity model and accompanying technical debt maturity assessment.
- Organizing classroom instruction and self-guided courses to evangelize best practices and community forums to drive continual engagement and sharing of resources.
- Tooling that supports the identification and management of technical debt (for example, indicators of poor test coverage, stale documentation, and deprecated dependencies).
In my opinion, the most interesting effort of this coalition is defining a maturity model around technical debt. This is similar to CMMI (a framework defined at Carnegie Mellon University) which provides a comprehensive integrated set of guidelines for developing products and services.
This defines a new way to approach the subject. Instead of relying on developer’s gut feeling and environmental factors, this maturity model has tracking at its core. This means that there are measurable metrics that will play a key part in informing an engineering team’s decision around technical debt.
Technical Debt Management Maturity Model
This model defines four different levels. From most basic to most advanced:
Reactive Level
"Teams with a reactive approach have no real processes for managing technical
debt (even if they do occasionally make a focused effort to eliminate it, for
example, through a “fixit”)."
In my experience, most engineering teams have the best intentions to make the right decisions, to ship good enough code, and to take on a reasonable amount of technical debt.
They understand that technical debt does not mean it is okay to ship bad code to production. They analyze the trade-offs of their decisions and they make their calls with that in mind.
Every now and then they will take some time (maybe a sprint or two) to pay off technical debt. When doing this, they usually address issues that they are familiar with because they’ve been hindered by those issues.
Non-technical leaders usually don’t understand the significance of taking on too much technical debt. They start to care once issues start popping up because of these issues. It might take a production outage, a security vulnerability, or extremely low development velocity to get them to react.
Proactive Level
"Teams with a proactive approach deliberately identify and track technical debt and make decisions about its urgency and importance relative to other work."
These teams understand that “if you can’t measure it, you can’t improve it.” So they have been actively identifying technical debt issues. They might have metrics related to the application, the development workflow, the release phase, and/or the churn vs. complexity in their application.
They understand that some of the metrics they’ve been tracking show potential issues moving forward. They might notice that their code coverage percentage has been steadily declining which could signal a slippage in their testing best practices.
They care about certain metrics that might help them improve their development workflow and they know that they need to first inventory their tech debt before taking action. They know that addressing some of these issues might improve their DORA metrics.
Strategic Level
"Teams with a strategic approach have a proactive approach to managing technical debt (as in the preceding level) but go further: designating specific champions to improve planning and decision making around technical debt and to identify and address root causes."
These teams have an inventory of technical debt issues. They build on top of the previous level. For example: They proactively address flaky tests in their test suite.
They might assign one person to one of the issues that they detected. They likely know how to prioritize the list of technical debt issues and focus on the most pressing ones.
Structural Level
"Teams with a structural approach are strategic (as in the preceding level) and also take steps to optimize technical debt management locally—embedding technical debt considerations into the developer workflow—and standardize how it is handled across a larger organization."
Improving the situation is a team effort. Non-technical managers treat tech debt remediation as any other task in the sprint. They likely reserve a few hours of every sprint to paying off technical debt.
Conclusion
After reading this paper, I wish the research team had shared more about the different maturity levels. I believe the software engineering community could greatly benefit from a “Technical Debt Management Maturity Model.”
It’s proof that while technical debt metrics may not be perfect indicators, they can allow teams who already believe they have a problem to track their progress toward fixing it.
The goal is not to have zero technical debt. It has never been the goal. The real goal is to understand the trade-offs, to identify what is and what is not debt, and to actively manage it to keep it at levels that allow your team to not be hindered by it.
Need help assessing the technical debt in your application? Need to figure out how mature you are when it comes to managing technical debt? We would love to help! Send us a message and let’s see how we can help!
]]>In our previous article Machine Learning: An Introduction to CART Decision Trees in Ruby, we covered CART decision trees and built a simple tree of our own. We then looked into our first ensemble model technique, Random Forests, in Machine Learning: An Introduction to Random Forests. It is a good idea to review that article before diving into this one.
Random Forests are great for a wide variety of cases, but there are also situations where they don’t perform quite as well. In this article we’ll take a look at another popular tree-based ensemble model: Gradient Boosting.
Introduction
Ensemble models are a pretty powerful technique. Conceptually, they can be built with any kind of weak learner, and can handle both regression and classification (binary or multi-class) tasks.
A weak learner is a model that is only slightly better than random choice. Considering a binary classification problem, if you pick a class at random for a particular instance, you have a 50% chance of being right. Weak learners are only slightly better than that.
For the purposes of this article, we’ll focus on a specific type of weak learner: decision trees. It is important to note that decision trees are weak learners when shallow and, in ensemble models, trees are kept intentionally shallow. A standalone tree can be a strong learner if allowed to grow complex enough.
We’ll also focus on a specific type of problem, the one applicable to the use case described in our Machine Learning Aided Time Tracking Review: A Business Case article, binary classification.
Brief Introduction to Gradient Boosting Classification
Gradient Boosting is a technique that builds a series of decision trees sequentially, with each individual tree designed to correct the errors made by previous trees. Instead of a “voting committee” approach like Random Forests, where predictions from individual trees are pooled and the most “voted” class is chosen, Gradient Boosting focuses on progressively reducing the residual errors of the model by using these residuals to train each new tree.
To make this easier to visualize, we can think of Gradient Boosting as a team of experts working towards an answer. Each new expert learns from the mistakes of the previous ones and gets a little bit closer to the answer. These “mistakes” are what’s called residuals.
The final prediction of the ensemble is then derived by combining the output of all the trees, effectively refining the accuracy of the model with each step. In other words, it iteratively enhances weak learners to build a robust and precise model that is effective in complex classification (and regression) tasks.
But why combine the output of all the trees to get a prediction if the last one is the most accurate?
Gradient Boosting is an additive process, meaning it relies on the “cumulative wisdom” of all these trees to work. The trees are sequential, they build upon the predictions of the previous trees, but don’t replace them. Each tree is trying to predict the residuals, not the actual target, so that the residuals get smaller with each tree, indicating the model is getting closer to the true target values. It’s a bit like a relay race, where each runner builds on top of the distance already run by the previous runner to get closer to the finish line. This also means the last tree is not fully informed, it only addresses the residuals that remain after all previous trees have made their contributions. For an actual target prediction, we need the cumulative contributions of all the trees.
Some important concepts to know when it comes to Gradient Boosting:
Boosting: Boosting is an ensemble technique that builds multiple weak learners sequentially, with each new tree correcting the errors of its predecessors. It constructs a decision tree, calculates the errors (distance between actual and predicted values) of the tree trained on the dataset, and then constructs a new tree focused on accurately predicting the errors of the first one. The predictions of the new tree are combined with the ones of the previous tree via a weighted sum, with more accurate trees being given more weight.
Loss Function: The loss function is the mathematical function that measures the difference between the values predicted by the model and the actual target values.
Gradient Descent: Optimization technique used to minimize the loss function by iteratively improving the model. The gradient in this context refers to the derivative (or rate of change) of the loss function with respect to the model’s predictions. Descent refers to the idea of moving in the opposite direction of the gradient to minimize said loss function. The gradient points towards the steepest increase in loss, so by moving in the opposite direction, we head towards reducing said loss (i.e. improving the model’s predictions). In Gradient Boosting, we often refer to fitting the trees to the “negative gradient”, which essentially means fitting the trees to the direction that will most reduce the loss, considering a negative gradient points to the direction of loss reduction, while the positive gradient would point towards increasing the loss.
Learning Rate: A regularization strategy that scales the contribution of each weak learner to control how fast the model learns. A lower rate means slower learning, while a higher rate means faster learning. It closely relates to the number of trees in the ensemble; lower learning rates will require a higher number of trees. However, it can lead to more robust models by not converging too quickly and helping avoid poor generalization and overfitting.
Odds: The ratio of the probability that an event will occur to the probability that it won’t. For an event with probability \(p\), it is defined as \(Odds = \frac{p}{1-p}\).
Log-Odds: The natural logarithm (logarithm to the base \(e\)) of the odds, defined as: \(LogOdds = ln(\frac{p}{1-p})\). Log-Odds are used in many implementations of Gradient Boosting for classification to make the initial prediction for each instance. The usage of log-odds helps transform the non-linear relationship between input features and the output into a more linear one, and provides a bounded range for the output, considering odds can range from 0 to infinity.
Representation of a Gradient Boosting classification process. Source: Improving Convection Trigger Functions in Deep Convective Parameterization Schemes Using Machine Learning by T. Zhang et al. (2021).
Gradient Boosting Classifier Algorithm
Gradient Boosting Classification works by sequentially building decision trees, with each new tree attempting to correct the errors made by its predecessors. Decision trees are built from the entire dataset, and the algorithm focuses on optimizing new trees by building them to correct the errors of the existing ensemble.
Before the first decision tree is built, an initial, very simple and naive prediction is made. The goal of the decision trees in Gradient Boosting is to minimize the loss function. Different loss functions are available, the default for Scikit-learn’s implementation being log-loss, which, for binary classification, is defined as
\[LogLoss = -ylog(p) - (1-y)log(1-p)\]Where \(y\) is the actual label (for binary classification, 0 or 1), and \(p\) is the probability of the instance in question belonging to the positive class (represented by 1).
This initial prediction (initial set of residuals) will be the log-odds of the class probabilities, calculated from the class distribution of the training data supplied.
Note that these residuals are real numbers, not probabilities, and per the log-loss definition, we need the probability of an instance belonging to the positive class. To turn a residual into a probability, we use the sigmoid function, defined as
\[\sigma(z) = \frac{1}{1+e^{-z}}\]The sigmoid function maps any real-valued number into the 0 to 1 range.
Now, we can calculate pseudo-residuals from this initial prediction. These will be the derivative of the log-loss function with respect to the predicted probability \(p\):
\[\frac{d}{dx}{(-ylog(p) - (1-y)log(1-p))} = \frac{-p + y}{p(1-p)}\]In the context of Gradient Boosting, the term \(\frac{1}{p(1-p)}\) can be ignored, as it scales the gradient but does not change its direction. Therefore, the gradient used to update the model will effectively be \(y-p\).
This is the negative gradient of the loss function, and it guides how to adjust the prediction to reduce the loss. The gradient represents the changes needed to the log-odds (natural logarithm of the ratio of the probability of an event happening to the probability of it not happening) of the predictions for the model to improve its accuracy. A positive gradient means the model should increase the log-odds of the particular instance being in the positive class (1) while a negative gradient suggests that the model should decrease the log-odds. It is important to remember that in Gradient Boosting, the residual indicates how much change is needed in the log-odds (not directly in target probability) to reduce the loss.
So we take the first set of residuals, convert it to probabilities, and then for each one calculate the difference between the probability and the actual class (gradient of the log-loss function) to get the pseudo-residuals.
The first decision tree is then constructed on the training data. Unlike a standalone decision tree, instead of predicting the actual target label, it attempts to predict the gradient of the loss function relative to the model’s predictions. Essentially, for this initial tree, it tries to predict the errors or differences between its own predictions and the true values. Practically, this means that instead of feeding the tree the dataset and labels, we feed it the dataset and pseudo-residuals.
The goal of the first tree is to predict these residuals as accurately as possible. Once it’s trained, for each sample in the dataset, we get the prediction of the decision tree. This prediction is then multiplied by a learning rate (between 0 and 1). If we consider \(F_m(x_i)\) the prediction of the model for the \(ith\) instance of \(x\) after \(M\) boosting iterations, the scaling of the contribution of that tree is defined as:
\[F_m(x) =F_{m-1}(x) + vh_m(x)\]Where \(v\) is the learning rate and \(h_m\) is the newly added tree.
The ensemble’s prediction is then updated with the prediction of the new tree, via weighted sum. Effectively, this means updating the first set of residuals with the first tree’s predictions for each sample, scaled by the learning rate.
The same process of converting the now updated residuals into probabilities using the sigmoid function and then calculating the pseudo-residuals is followed; and a second tree can be constructed to predict these pseudo-residuals, thus learning from the mistakes of the first tree. Similarly, once it’s trained, its own predictions will be scaled based on the learning rate and used to update the ensemble’s predictions.
The process of adding a new tree, calculating the pseudo-residuals, training the tree, scaling the tree’s predictions and updating the residuals of the ensemble is repeated until a specified maximum number of trees is reached or until adding more trees does not significantly decrease the loss function. The model then outputs its prediction, which is the weighted sum of predictions from all the trees in the ensemble up to that point. This total can be any number on the number line and can be represented as:
\[F_m(x) = \sum_mh_m(x_i)\]For classification tasks, we want a probability between 0 and 1, not any real number. Therefore, the result of the sum needs to be converted into a probability. To do so, we need to map the value of the prediction \(F_m(x_i)\) to a class or a probability, based on the loss function. The probability that a given instance of \(x\) belongs to the positive class (1) is:
\[p(y_i=1|x_i) = \sigma(F_m(x_i))\]where \(\sigma\) is the sigmoid function of \(F_m(x_i)\).
This transformation helps determine which class a prediction belongs to by using a decision threshold, typically 0.5 for binary classification.
Building a Gradient Boosting Classifier
Now that we have a good understanding of Gradient Boosting and gradient boosted trees, let’s leverage our DecisionTree class and build a very simple GradientBoostingClassifier of our own.
The DecisionTree class here refers to an individual decision tree. For more information on decision trees and a simple sample implementation, check out our Machine Learning: An Introduction to CART Decision Trees in Ruby article.
Like with the DecisionTree, we want a train method and a predict method. The difference is the train method of the classifier will call the DecisionTree’s train method on the pseudo-residuals of the original data.
First, we’ll initialize three things we’ll need: the maximum number of trees to construct, the learning rate we want, and the maximum depth we want for each individual tree in the ensemble. We’ll need to store the trees in an array and to store the prediction.
def initialize(max_tree_depth: 3, n_trees: 100, learning_rate: 0.1)
@n_trees = n_trees
@learning_rate = learning_rate
@max_tree_depth = max_tree_depth
@trees = []
@initial_prediction = nil
end
Our train method will take in two variables: the data to train on and the target labels for the dataset. We first need to initialize the model and calculate the log-odds of the positive class, so we can calculate the first set of residuals:
positive_probability = labels.count(1).to_f / labels.size
@initial_prediction = Math.log(positive_probability / (1 - positive_probability))
residuals = Array.new(labels.size, @initial_prediction)
Now, for as many trees as specified, we’ll convert these log odds to probabilities, calculate a set of pseudo-residuals associated with them, and use these pseudo-residuals to train a new tree. Finally, for each new trained tree, we’ll update the total residuals (log odds) of the ensemble.
@n_trees.times do
probabilities = residuals.map { |log_odds| 1.0 / (1.0 + Math.exp(-log_odds)) }
pseudo_residuals = labels.zip(probabilities).map { |y, prob| y - prob }
tree = DecisionTree.new
tree.train(data, pseudo_residuals, max_tree_depth)
@trees << tree
data.each_with_index do |sample, index|
tree_prediction = tree.predict(sample)
residuals[index] += @learning_rate * tree_prediction
end
end
That concludes our train method.
For the prediction, our predict method needs to, for each tree, gather its individual prediction and update the residuals (log odds) of the ensemble.
It will then convert the final number to a probability and return the binary class prediction. Assuming a decision threshold of 0.5:
def predict(sample)
log_odds = @initial_prediction
@trees.each do |tree|
prediction = tree.predict(sample, 0) # zero here is the default label to be used in case a standard prediction cannot be made for any reason
log_odds += @learning_rate * prediction
end
probability = 1.0 / (1.0 + Math.exp(-log_odds))
probability >= 0.5 ? 1 : 0
end
Putting it all together, we have a very simple Gradient Boosting Classifier:
require_relative "decision_tree"
class GradientBoostingClassifier
attr_accessor :n_trees, :learning_rate, :max_tree_depth, :trees, :initial_prediction
def initialize(max_tree_depth: 3, n_trees: 100, learning_rate: 0.1)
@n_trees = n_trees
@learning_rate = learning_rate
@max_tree_depth = max_tree_depth
@trees = []
@initial_prediction = nil
end
def train
positive_probability = labels.count(1).to_f / labels.size
@initial_prediction = Math.log(positive_probability / (1 - positive_probability))
residuals = Array.new(labels.size, @initial_prediction)
@n_trees.times do
probabilities = residuals.map { |log_odds| 1.0 / (1.0 + Math.exp(-log_odds)) }
pseudo_residuals = labels.zip(probabilities).map { |y, prob| y - prob }
tree = DecisionTree.new
tree.train(data, pseudo_residuals, max_tree_depth)
@trees << tree
data.each_with_index do |sample, index|
tree_prediction = tree.predict(sample)
residuals[index] += @learning_rate * tree_prediction
end
end
end
def predict(sample)
log_odds = @initial_prediction
@trees.each do |tree|
prediction = tree.predict(sample, 0)
log_odds += @learning_rate * prediction
end
probability = 1.0 / (1.0 + Math.exp(-log_odds))
probability >= 0.5 ? 1 : 0
end
end
We’re all set! We now have a very simple Gradient Boosting Classifier of our own. Like with Random Forest, for actual use cases, we need a much more robust algorithm which is, again, why we used Scikit-learn to build our own. The goal of this demonstration is to explain the basic concepts behind how this kind of classification works.
For more information on Scikit-learn’s implementation of Gradient Boosting Classifiers and how to use them, check out their documentation.
Conclusion
First, we built our very own decision tree. Now we have built two different kinds of ensemble models: Random Forests and Gradient Boosting classifiers. As you can image, though, Gradient Boosting can be quite slow, as all trees are built sequentially. Next in this series we’ll take a look at more advanced implementations of the Gradient Boosting algorithm: XGBoost (eXtreme Gradient Boosting) and LightGBM (Light Gradient Boosting Machine). These implementations offer improved speed, performance and some additional features compared to traditional Gradient Boosting methods.
Excited to explore the world of Machine Learning and how it can be integrated into your application? We’re passionate about building interesting, valuable products for companies just like yours! Send us a message over at OmbuLabs!
]]>When dealing with large and complex data, or when dealing with data with a significant amount of noise, we need something more powerful. That’s where ensemble models come into play. Ensemble models combine a number of weak learners to build a strong model, with increased accuracy and robustness. Ensembles also help manage and reduce bias and overfitting.
In this article, we’ll cover a very popular tree-based ensemble model: Random Forest.
Introduction
Ensemble models are a pretty powerful technique. Conceptually, they can be built with any kind of weak learner, and can handle both regression and classification (binary or multi-class) tasks.
A weak learner is a model that is only slightly better than random choice. Considering a binary classification problem, if you pick a class at random for a particular instance, you have a 50% chance of being right. Weak learners are only slightly better than that.
For the purposes of this article, we’ll focus on a specific type of weak learner: decision trees. It is important to note that decision trees are weak learners when shallow and, in ensemble models, trees are kept intentionally shallow. A standalone tree can be a strong learner if allowed to grow complex enough.
We’ll also focus on a specific type of problem, the one applicable to the use case described in our Machine Learning Aided Time Tracking Review: A Business Case article, binary classification.
Brief Introduction to Random Forest Classification
Random Forests operate by constructing multiple decision trees, pooling the class prediction outputted by each individual tree and choosing the class with the most votes (mode) as the final prediction to output.
A few interesting concepts to know when dealing with Random Forests:
Bootstrapping: a statistical resampling technique that involves, in the context of Random Forests, creating multiple subsets of the original training dataset by drawing each subset randomly with replacement; that is, after each draw, the selected item is put back into the original set and can be picked up again. This means that at the end of the process, each tree gets a subset of data, and different subsets might have repeating data points.
Bagging: Bagging, short for Bootstrap Aggregating, is an ensemble technique that trains multiple weak learners (which, in the case of Random Forest, are individual decision trees) independently on different bootstrap samples and then aggregates their predictions to produce a final prediction.
The combination of bootstrapping and bagging is what helps reduce variance in the model, allowing for more robust and accurate models. It ensures each tree in the group is different, which is crucial for the team of trees to work well together and deal with complicated patterns in data. As an added plus, since each tree can be trained independently, Random Forests are highly parallelizable, making them efficient on large datasets.
Implementation of a Random Forest classifier. Source: Machine Learning for Subsurface Characterization by Siddharth Misra and Hao Li
Random Forest Classifier Algorithm
Random Forest classification works by training multiple individual trees and taking the individual predictions to arrive at a final one. One key difference to keep in mind is that decision trees constructed by a Random Forest classifier are constructed from bootstrap-sampled data, not from the total dataset.
To construct the trees, multiple subsets of the original data are created via bootstrapping. These subsets will compose the root node of each tree.
For classification, as you may recall from the previous article on CART decision trees, Gini impurity is used to define the feature and threshold to split on, with the goal being to always minimise impurity in the set. It is also possible to use Information Gain to split the dataset, but in this article we’ll focus on Gini impurity.
At each split, a random subset of features is chosen, with the best split being found within this subset. In standard implementations of Random Forest, including Scikit-learn’s, the sample is the same size as the original dataset, but the composition of features and instances will vary. The randomness aspect increases the diversity of the trees, helping make the model more robust and reducing overfitting.
Each tree in the forest yields a classification. Considering a forest with \(K\) trees, each yielding a prediction \(C_k(x)\) of the Kth tree for input x, the final prediction is:
\[Y(x) = mode{C_1(x), C_2(x), ..., C_K(x)}\]Where mode refers to the most frequent class label among all the class labels predicted by the individual trees in the forest.
Building a Random Forest Classifier
Now that we have a good understanding of Random Forests, let’s leverage our DecisionTree class from the previous article and build a very simple RandomForestClassifier of our own.
Like with the DecisionTree, we want a train method and a predict method. The difference is the train method of the classifier will call the DecisionTree’s train method on a random subset of the original data.
First, we’ll initialize a couple of things we’ll need: the number of trees to construct and the maximum depth of each tree. We’ll need to store the trees in an array.
def initialize(n_trees, max_depth)
@n_trees = n_trees
@max_depth = max_depth
@trees = []
end
In order to train the individual trees, we’ll need bootstrapped samples. Let’s define a private method to randomly select samples from the original dataset that we can use to train the trees:
def bootstrap_sample(data, labels)
bootstrapped_data = []
bootstrapped_labels = []
n_samples = data.length
n_samples.times do
index = rand(n_samples)
bootstrapped_data << data[index]
bootstrapped_labels << labels[index]
end
[bootstrapped_data, bootstrapped_labels]
end
Now we can build our train method. All it needs to do is, for as many times as the number of trees defined, train a DecisionTree on a bootstrapped sample, and store the tree in the array of trees:
def train(data, labels)
@n_trees.times do
tree = DecisionTree.new
bootstrapped_data, bootstrapped_labels = bootstrap_sample(data, labels)
tree.train(bootstrapped_data, bootstrapped_labels, @max_depth)
@trees << tree
end
end
Finally, for the prediction, our predict method needs to gather individual predictions for each one of the trees and return the mode of those predictions:
def predict(sample)
predictions = @trees.map { |tree| tree.predict(sample, nil) }.compact
return nil if predictions.empty?
predictions.group_by(&:itself).values.max_by(&:size).first
end
Putting it all together, we have a simple Random Forest Classifier:
require_relative "decision_tree"
class RandomForestClassifier
attr_accessor :n_trees, :max_depth, :trees
def initialize(n_trees, max_depth)
@n_trees = n_trees
@max_depth = max_depth
@trees = []
end
def train(data, labels)
@n_trees.times do
tree = DecisionTree.new
bootstrapped_data, bootstrapped_labels = bootstrap_sample(data, labels)
tree.train(bootstrapped_data, bootstrapped_labels, @max_depth)
@trees << tree
end
end
def predict(sample)
predictions = @trees.map { |tree| tree.predict(sample, nil) }.compact
return nil if predictions.empty?
predictions.group_by(&:itself).values.max_by(&:size).first
end
private
def bootstrap_sample(data, labels)
bootstrapped_data = []
bootstrapped_labels = []
n_samples = data.length
n_samples.times do
index = rand(n_samples)
bootstrapped_data << data[index]
bootstrapped_labels << labels[index]
end
[bootstrapped_data, bootstrapped_labels]
end
end
We’re all set! We now have a very simple Random Forest Classifier of our own. Of course, for actual use cases, we need a much more robust algorithm, which is why we used Scikit-learn (and thus Python) to build our own. The goal of this demonstration is to explain the basic concepts behind how the classification works.
It’s also important to note that, as of the writing of this article, there wasn’t necessarily an “equivalent” to Scikit-learn in Ruby in terms of robustness and maturity of the platform.
The rumale gem does a great job of implementing Random Forest in Ruby, but given the other aspects of the process, including data processing, encoding, visualization, among others, we decided to use Scikit-learn on our implementation.
For more information on Scikit-learn’s implementation of Random Forests, check out their documentation.
Conclusion
First, we built our very own decision tree. Now, we have made our model more robust by building an ensemble model, our very own Random Forest. This kind of algorithm is quite popular and widely used in a variety of different machine learning applications.
As you can imagine, though, there are situations where Random Forest’s voting approach is not the best. Random Forests sometimes struggle with very complex decision boundaries or highly imbalanced datasets, they may not significantly reduce bias as individual decision trees might have high bias, and errors might compound as trees are built independently. Gradient Boosting is a different ensemble model technique that aims to help with some of these limitations by trying to correct the errors of previous trees with each new tree. Next in this series, we’ll look at Gradient Boosting Classifiers and how they do that.
Excited to explore the world of Machine Learning and how it can be integrated into your application? We’re passionate about building interesting, valuable products for companies just like yours! Send us a message over at OmbuLabs!!
]]>